SEOの知識を学び、相当の努力もしているのに、成果が出せない人がいる。
そんな人たちに共通するのは、「検索エンジンの仕組み」を理解していないことだ。
あまりに基本的すぎると感じるせいか、基礎を押さえるより先にテクニックに走ってしまう。
この記事では、何年も経ってから、
「あのとき立ち止まり、時間を割いて、検索エンジンの仕組みを学んでいれば……」
と後悔しないで済むように、SEOに必要な検索エンジンの基礎知識をまとめた。
本記事が提供するのは、
「検索エンジンの仕組みと、実践すべきSEO対策をセットにしたレクチャー」
である。
これからSEOにチャレンジする人も、「今さら聞けない基本のキ」を知りたいという人も、一読したうえでSEOを実践してほしい。得られる成果に差が出るはずだ。
なお、記事の最後には「マニアックな技術的情報を知りたい」という人向けに、論文や特許の情報も掲載している。参考にしてほしい。


目次
1. 検索エンジンの概要
まず、検索エンジンについて、大枠の概要から把握していこう。
1-1. そもそも「検索エンジン」とは?
そもそも検索エンジンとは何かといえば、
「インターネットユーザーが、キーワードを使って、探している情報を見つけるために構築されたシステム」
を指す。
具体例として多くの人が思い浮かべるのは、いうまでもなく「Google」だろう。
他に、「Yahoo!」や「Bing」などもあるが、Yahoo!JAPANは、2010年にGoogleを検索エンジンとして採用して独自開発をやめ、ポータルサイトとして進化を遂げて今がある。
世界的なシェアを見てみると、Googleが90%以上と、圧倒的である。

1-2. 検索エンジンの基本的な挙動(ユーザー視点)
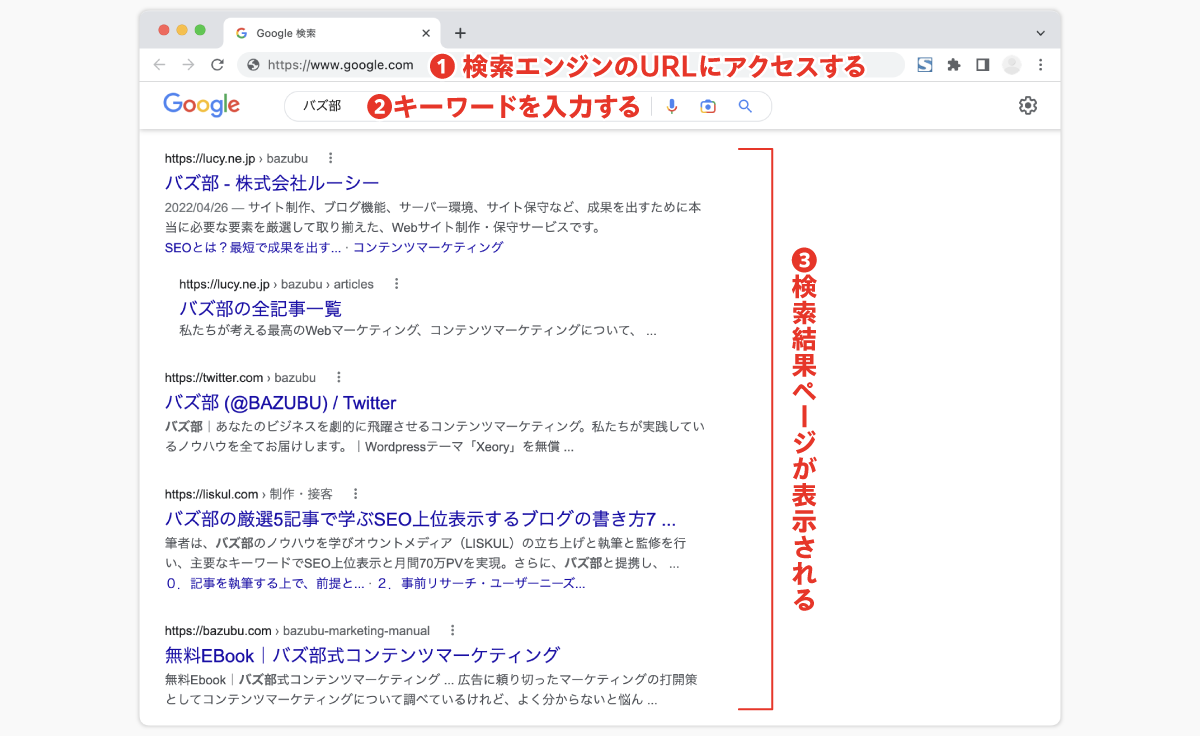
ユーザーの視点から見たとき、検索エンジンの基本的な挙動は、以下のとおりだ。
- 検索エンジンのURLにアクセスする(例:https://www.google.com/)
- 入力欄(検索窓)に、キーワードを入力して、エンターキーをクリックする。
- 検索結果ページが表示される。
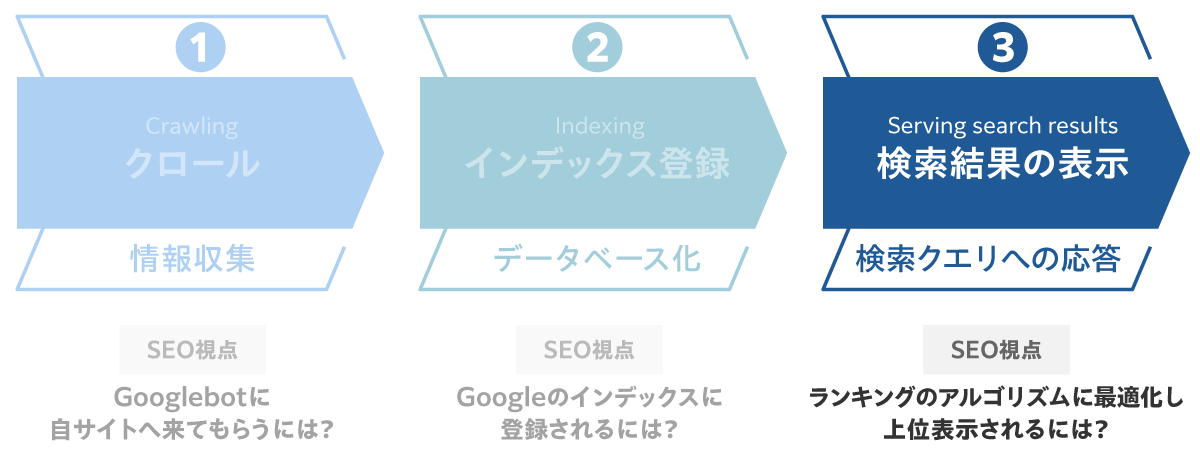
1-3. 検索結果が表示されるまでの3つのプロセス(検索エンジン側)
ユーザーに「検索結果ページ」が提供される裏側の仕組みとして、検索エンジンでは以下3つのプロセスが実行されている。
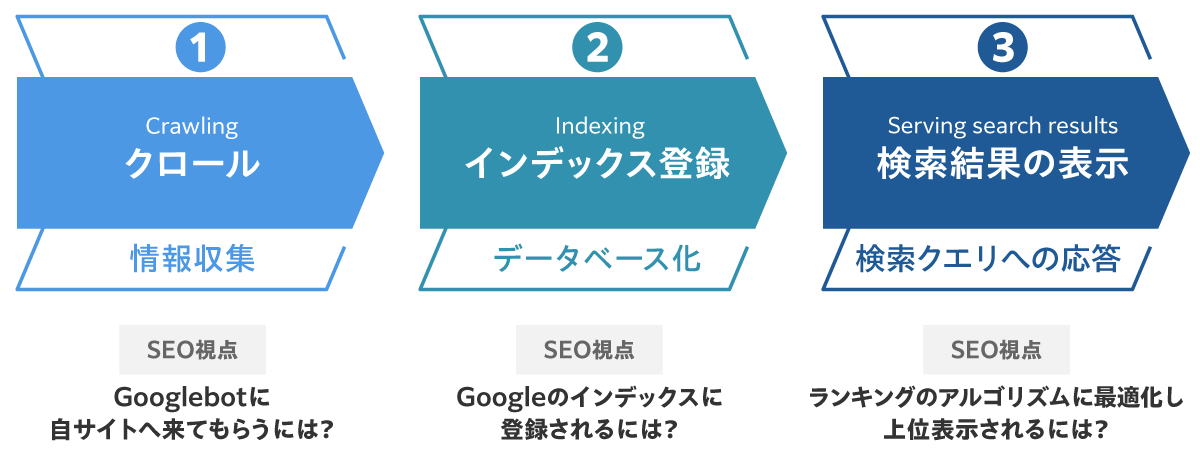
(1)クロール、(2)インデックス登録、(3)検索結果の表示、この3つの仕組みについて、以降で詳しく見ていくことにしよう。






2. 検索エンジンの仕組み(1)クロール
まずは第一のステップである「クロール」を解説する。
2-1. クロールとは?
クロールとは、検索エンジンのボット(スパイダーともいう)が、インターネット上のWebサイトを巡回して、サイトやページを発見するプロセスである。
「クロール(crawl)」という泳ぎ方があるが、ここでいうクロールも同じ「crawl」だ。“這う、腹ばいで進む”といった意味がある。
スパイダー(=クモ)のように、ボットがネット上を這い回って巡回することを、クロールという。
クロールするボットは「クローラー」と呼ばれ、Googleのメインクローラーには「Googlebot」という名前がついている。
2-2. クローラーは「インターネットの蜘蛛の巣=リンク」を這って回る
ここで非常に重要なポイントは、
「クローラーは、インターネットの蜘蛛の巣=リンクによってつながった巨大空間を、リンクをたどって這い回る」
ということだ。
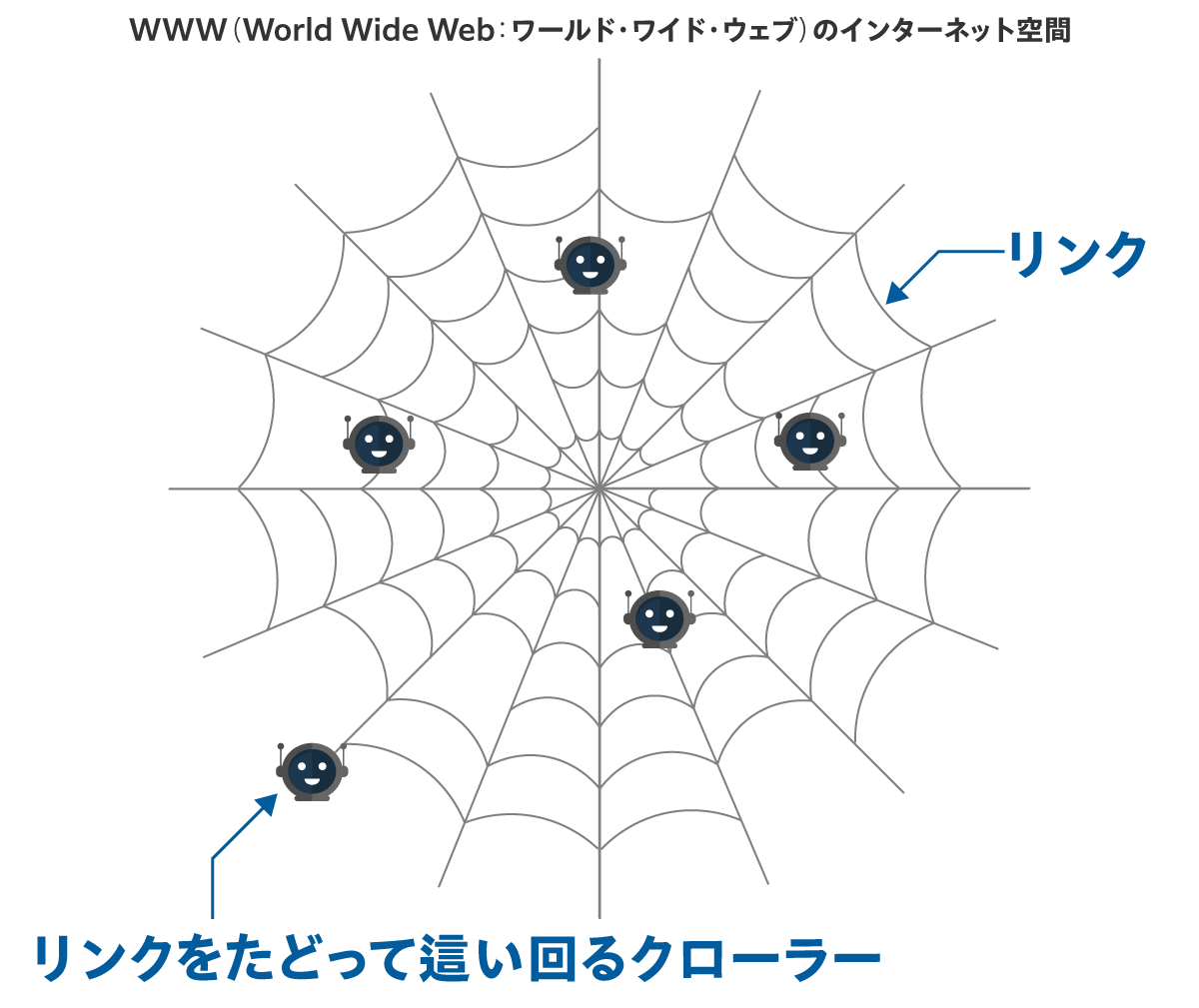
クローラーは、既知のページから張られているリンクをたどって、新しいページを検知する。
どこのページからもリンクを張られておらず、「ポツンと一軒家」状態で孤立しているページには、クローラーは来られない。
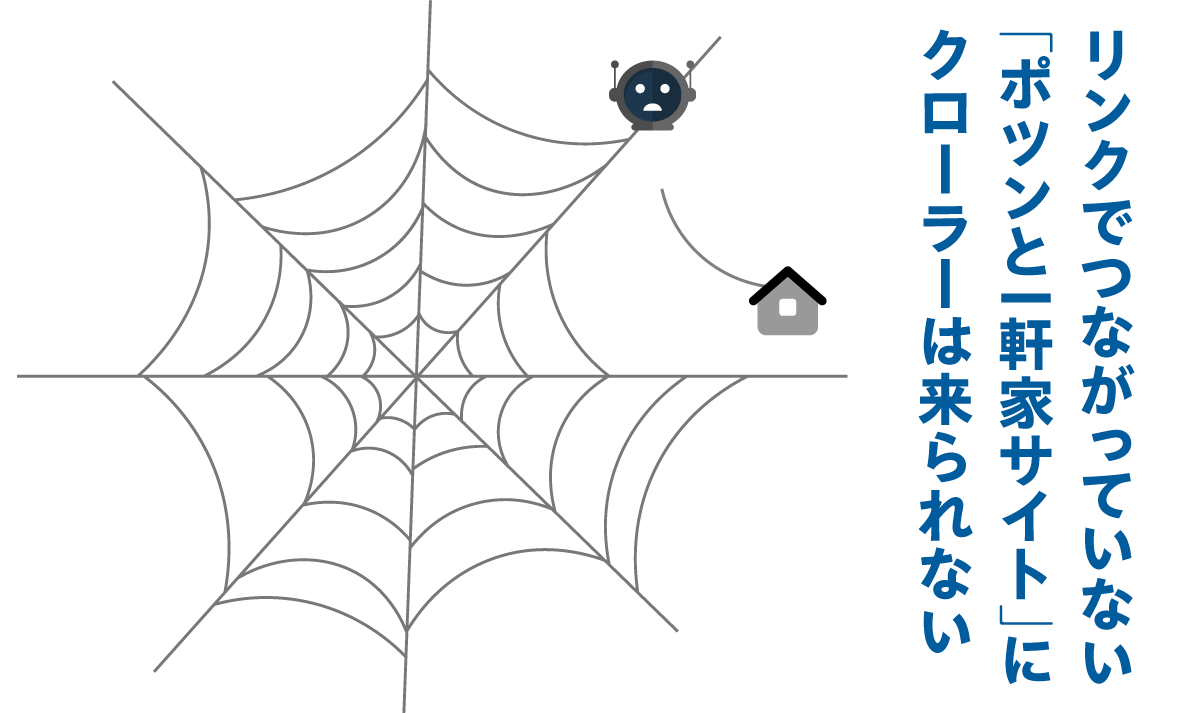
自サイトへクローラーに来てもらうためには、蜘蛛の巣に入る必要がある。すなわち、他ページからリンクされる、ということだ。
2-3. クロールされるためのSEO対策
SEOにおいては、まずクローラー(Googlebot)がサイトにやってきて、ページをクロールしてくれないことには、始まらない。
クロールされるためのSEO対策として、基本の3項目を紹介しよう。
- 既知のページからリンクされる
- XMLサイトマップを送信する
- robot.txt でdisallow(拒否)しない
1:既知のページからリンクされる
繰り返しになるが、クローラーは「リンク」をたどってやってくる。
新しいページを作ったら、既存ページからリンクされることが重要だ。
他サイトからの被リンクを受け取るほか、内部リンクを張り巡らせることによって、孤立ページを作らない工夫をしよう。
「内部リンクとは?SEOでの重要性と効果が出る張り方のコツ」の内容を実践してほしい。
2:XMLサイトマップを送信する
理想は、自然なリンクを張り巡らせることだ。しかし、それが難しいケースもある。とくに、新しいサイトを作ったばかりのときは、被リンクを獲得するのが難しい。
そんなときに、リンクの代替として使えるのが「XMLサイトマップ」である。
XMLサイトマップは、クローラー向けに作成する、サイト内のページを網羅したURLリストだ。実物を見てみよう。
▼ バズ部のサイトマップ
https://lucy.ne.jp/bazubu/sitemap.xml
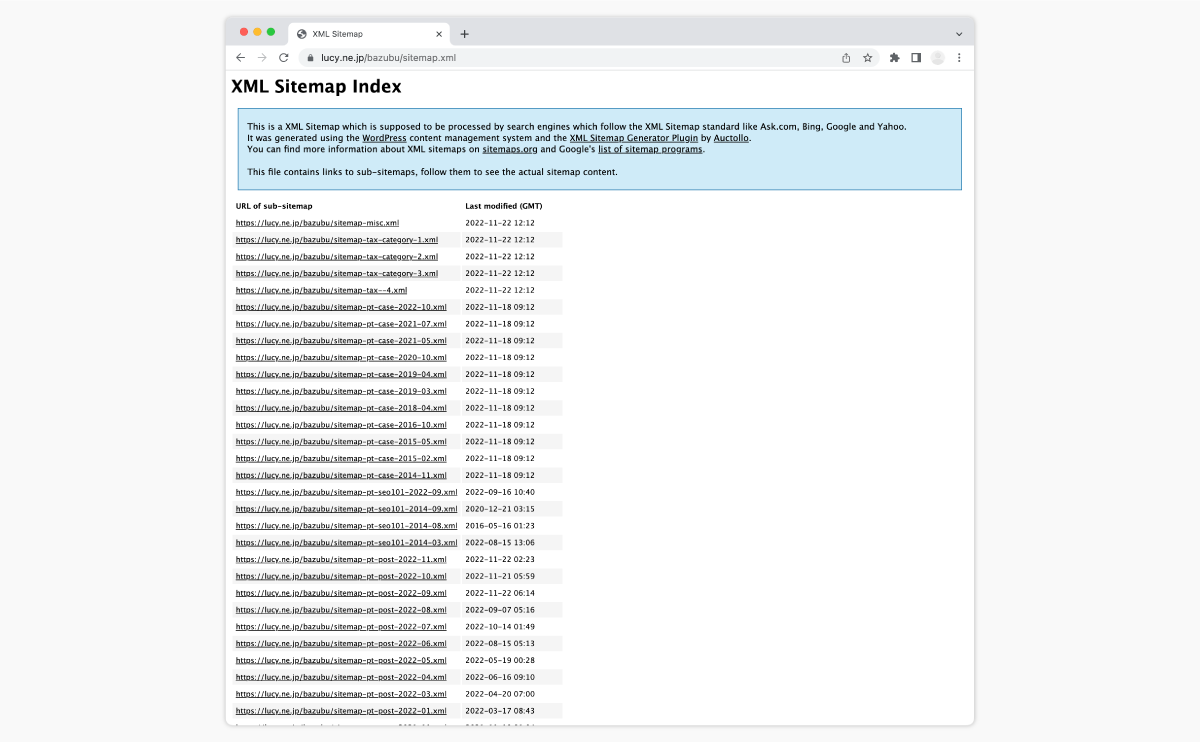
ご覧いただくとわかるとおり、サイト内に存在する全ページのリンク集になっている。
XMLサイトマップを作成すれば、サイトマップページからのリンクをたどって、クローラーが全ページにたどり着ける。
詳しいやり方は「XMLサイトマップとは?SEO効果や作成方法を分かりやすく解説」をチェックしよう。
3:robot.txt でdisallow(拒否)しない
「robot.txt」というファイルがある。これは、クローラーに対して、サイトのどのURLにアクセスしてよいか、伝えるものだ。
▼ robot.txtの例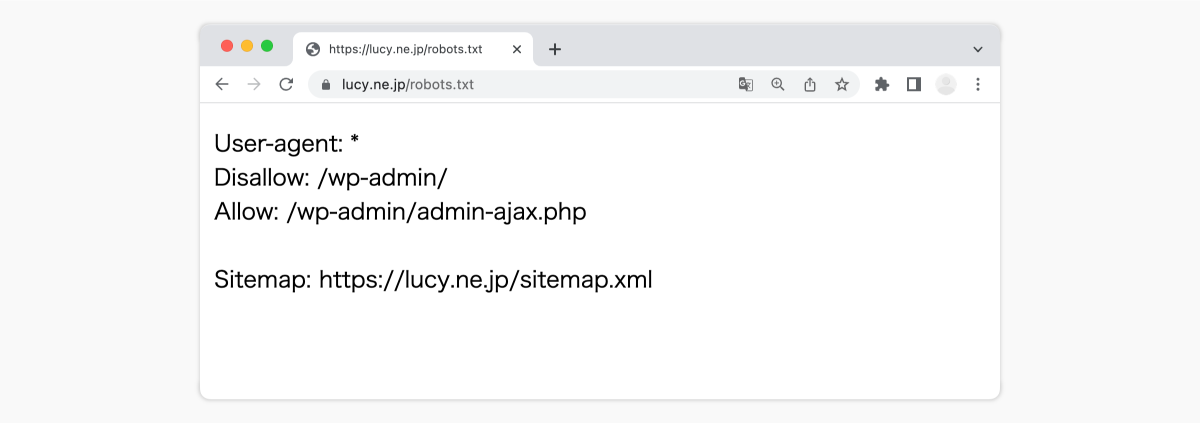
robot.txt でクロールを拒否する設定(disallow)をしていると、クローラーはその指示に従って、クロールしない。
「robots.txtとは?設置する理由・SEO効果・書き方を解説」を確認し、自サイトのrobot.txtの状況をチェックしておこう。
3. 検索エンジンの仕組み(2)インデックス登録
無事にクローラーがやってきたら、次のプロセスは「インデックス登録」となる。
3-1. インデックスとは?
インデックス(index)とは、「索引、見出し」といった意味の単語だ。
Googleでいうインデックスとは、クローラー(Googlebot)が訪問したページのコンテンツを解析して、Googleのデータベースに保存することをいう。
Googleの検索結果ページに表示されるのは、インデックスされたページのみだ。インデックスされなかったページは、検索結果ページに表示されることはない。
3-2. Googleの目的はWebページのコレクションではない
Googleは、どんな基準で「インデックスをする/しない」を判断するのだろうか。
Googleの意図を理解するために、ここでGoogleのミッションを確認しておこう。
Googleの使命は、世界中の情報を整理し、世界中の人がアクセスできて使えるようにすることです。
出典:Google
勘違いしている人がいるので明確にしておきたいのだが、Googleの目的は、世界中のWebページをすべてコレクションすることではない。
収集した情報を整理して、ユースフルに(使えるように)するのが、Googleのミッションだ。
情報の整理には、検索ユーザーにとって無価値なもの・有害なもの・重複するものを排除することも、含まれる。
Googleが、検索ユーザーにとって価値がないと判断したページは、インデックスされない、ということである。
3-3. インデックス登録のためのSEO対策
Googleの意図を踏まえつつ、インデックス登録されるために実践すべきSEO対策は、以下のとおりだ。
● 価値のあるコンテンツを作る
● 正規URLを設定する
● noindex を設定しない
● 手動によるペナルティ・セキュリティの問題を解決する
それぞれ見ていこう。
1:価値のあるコンテンツを作る
何をおいても、最も重要なのは「価値のあるコンテンツ」である。
ユーザーにとって価値のある、良質なコンテンツほど、インデックス登録される可能性は高くなる。
「良質なコンテンツを、どうやれば作れるか?」
という問いには、ここで答えるにはスペースが足りないので、有益な記事を以下に紹介する。
じっくりと目を通したうえで、コンテンツづくりに取り組んでほしい。
2:正規URLを設定する
正規URLとは、類似したコンテンツで複数のURLが存在する場合に、代表として1つだけインデックス登録されるURLのことである。
Googleにとって、同じ情報のURLを複数、インデックス登録するのは無駄である。
よって1つだけを選んで登録するわけだが、サイト運営者が登録してほしいURLが却下され、しなくてもよいURLが採用されることがある。
そこで、Googleに対して「正規URLはこれです」と、明示的に示す作業が「正規化URLの設定」である。
やり方は、いくつかオプションがある。
● canonicalタグ
● 301リダイレクト
● alternateタグ
● XMLサイトマップ
詳しくは「URLの正規化とは?具体的な方法と正規化すべきケースを解説」を確認して、進めてほしい。
3:noindex を設定しない
「noindex」は、HTML(metaタグ)でページに対して設定できる値であり、「インデックスに登録せず、検索結果に表示しないようにする」ことを指示する。
<meta name=“robots” content=“noindex”> #検索エンジン全般
<meta name=“googlebot” content=“noindex”> #Googleのみ
検索結果ページに表示させたくないURLがあるときに使うものだが、意図せずnoindex設定をしていると、インデックスされないので注意しよう。
自分でタグを書き入れた覚えはなくても、WordPressなどで誤って設定してしまうと、noindexのタグが反映されてしまう。
意外とよくあるケアレスミスが、サイト立ち上げ前の準備中にnoindexに設定したまま、解除するのを忘れることだ。
▼ WordPressの設定画面の例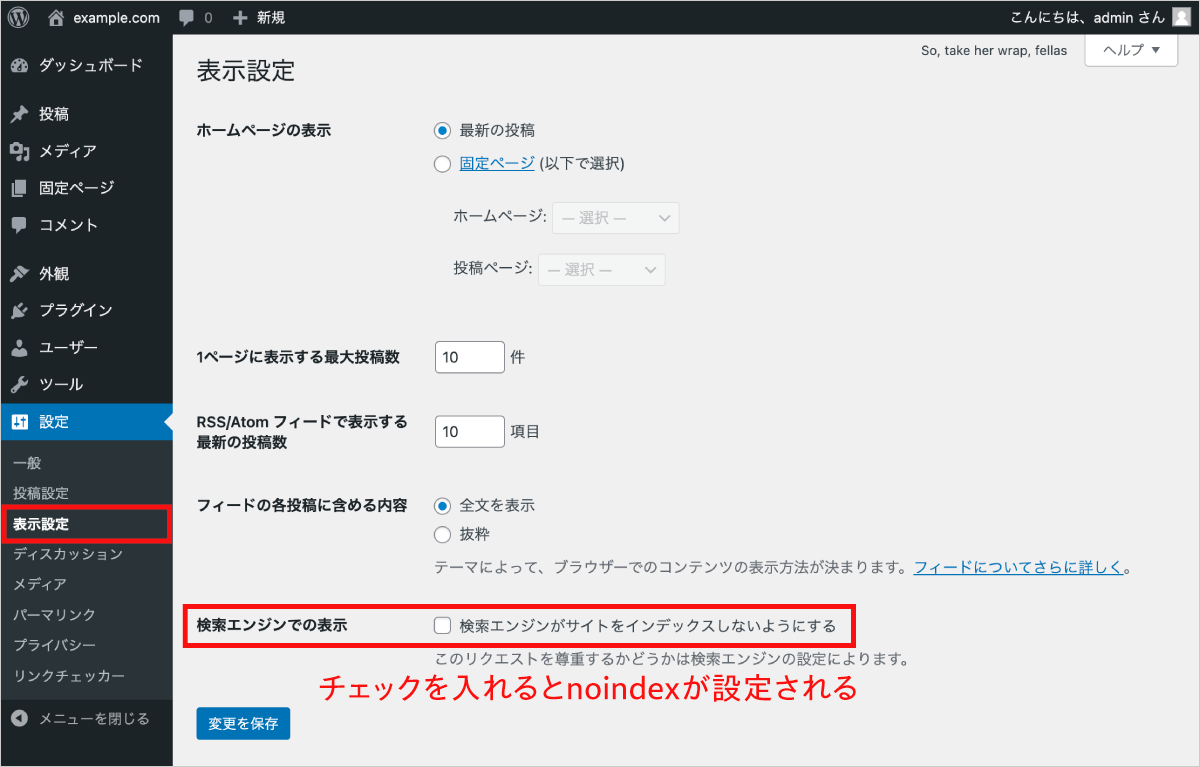
「noindexとは?設定方法や注意点を分かりやすく解説」を参考にして、確認しておこう。
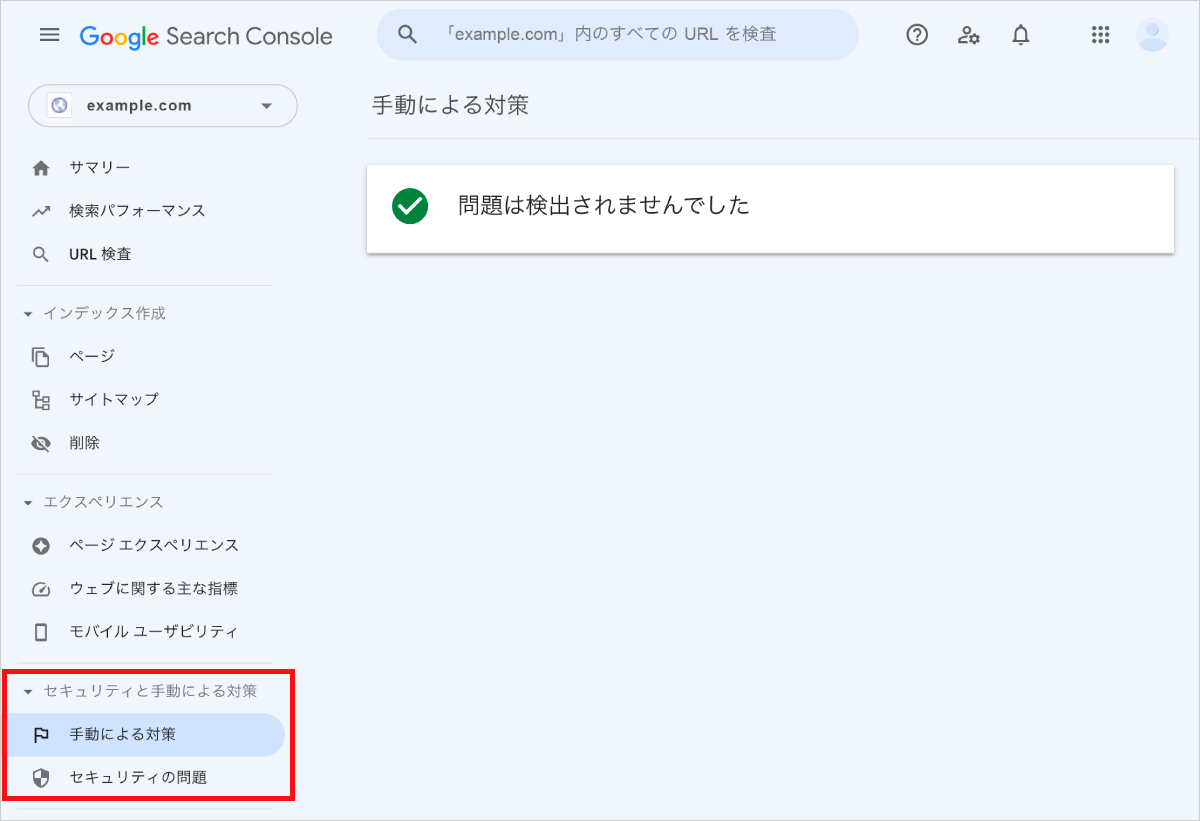
4:手動によるペナルティ・セキュリティの問題を解決する
Googleから、何かしらのペナルティ(手動によるアクション)やセキュリティの問題が生じている場合、インデックス登録が見合わされる。
たとえば、購入したドメインや他者から引き継いだサイトの場合、注意が必要だ。
Google Search Console(*1)にて、Googleから[セキュリティと手動による対策]に通知が届いていないか、確認しよう。
詳しくは以下を参照してほしい。
*1:Google Search Consoleは、SEOに必要な情報をレポートとしてGoogleから受け取れる、Google提供の無料ツールである。SEOに必須のアイテムだ。
まだ導入していない場合は、「Google Search Consoleとは?初心者向けにキャプチャ付で解説」をチェックしよう。
以上、基本事項を中心にお伝えした。「インデックスとは?SEOに初めて取り組む人向けの重要知識まとめ」にも目を通すと、より深く理解できるだろう。
4. 検索エンジンの仕組み(3)検索結果の表示
最後に、Googleが検索結果を表示するプロセスを見ていこう。
4-1. 検索結果を表示の裏でGoogleが行っている処理
検索ユーザーがキーワードをGoogleの検索窓に入力してエンターキーを押し、検索結果ページが表示されるまでの間に、Googleは何を行っているのだろうか。
ごく簡略化して示せば、以下のとおりとなる。
- ユーザーインテント(検索の意図)を理解する
入力された語句(検索クエリ)を解釈し、検索ユーザーが知りたい情報や成し遂げたいタスクは何か推察する。
たとえば[Apple]という語句が、Macの会社なのか果物なのか人の名前なのか街なのか……といった具合である。 - 理解したユーザーインテントに対してベストなURLを抽出し、検索結果ページを生成して表示する
検索ユーザーが、最も十分に満足すると推測されるURLから順番に、インデックス(データベース)から抽出して並べる。
ユーザーインテントとページの関連性、情報源の専門性、ユーザビリティ、ユーザーの位置・設定など、多くの要因やシグナルが考慮される。
各要素の重みは、検索クエリの性質によって変わる。
4-2. Googleが処理に使うアルゴリズムは200以上
検索ユーザーが入力した語句を解釈したり、ベストなURLを抽出したりする処理に使われるのが「アルゴリズム」だ。
ここでいうアルゴリズムとは、「指定した動作を実行する命令や計算式」と捉えておこう。
〈Google がランキングの決定に使用している 200 以上のシグナル〉
という表現があることから、少なくとも200以上のアルゴリズムが存在し、年月の経った現在では倍増している可能性もあるだろう。
4-3. アルゴリズムの5つのタイプ
Googleのアルゴリズムの詳細は明かされていないものの、「Google 検索の仕組み」によれば、次の5つに大別できることがわかる。
検索クエリの意味 | 言語モデル(人工知能)を使い、検索ユーザーの意図を理解するアルゴリズム |
コンテンツの関連性 | コンテンツを分析して、求められている内容に関連する可能性のある情報が含まれているか評価するアルゴリズム |
コンテンツの質 | 関連性のあるコンテンツの中から最も役立ちそうなコンテンツを優先するために、専門性・権威性・信頼性を判定するアルゴリズム |
ユーザビリティ | コンテンツの関連性・質に大差がない場合は、ユーザーにとってのアクセス性が高いコンテンツを優先するアルゴリズム |
コンテキストと設定 | 所在地やGoogle検索設定も考慮して、検索結果を生成するアルゴリズム |
※アルゴリズムの詳細は「Googleのアルゴリズムとは?2022最新アップデートから対策まで解説」に詳しい。
4-4. 検索結果表示のためのSEO対策
以上を踏まえて、実践すべきSEO対策は以下のとおりだ。
- 明確にキーワードを選定してコンテンツを作る
- 専門性・権威性・信頼性を高める
- ユーザビリティを高める
1:明確にキーワードを選定してコンテンツを作る
意外と意識している人が少ないのが、Googleは「コンテンツの“質”の前に、コンテンツの“関連性”」でコンテンツをふるいにかけている事実である。
先ほど紹介した「4-3. アルゴリズムの5つのタイプ」を、もう一度確認してみてほしい。
つまり、どんなにコンテンツの質が高くても、検索クエリ(検索ユーザーが入力した語句)との関連性がないコンテンツは、検索結果ページに登場し得ない。
検索クエリとの関連性を強めるために重要なのが「キーワード選定」である。
キーワード選定とは、言い換えれば「関連性を強めたい、ターゲットの検索クエリは何か?」の的を絞り、そこに力を集中させることである。
キーワード選定の詳細は、以下のページを参照してほしい。
2:専門性・権威性・信頼性を高める
「専門性・権威性・信頼性」とは、Googleがコンテンツの質を評価する指標として重視している概念である。頭文字をとってE-A-Tと呼ばれる。
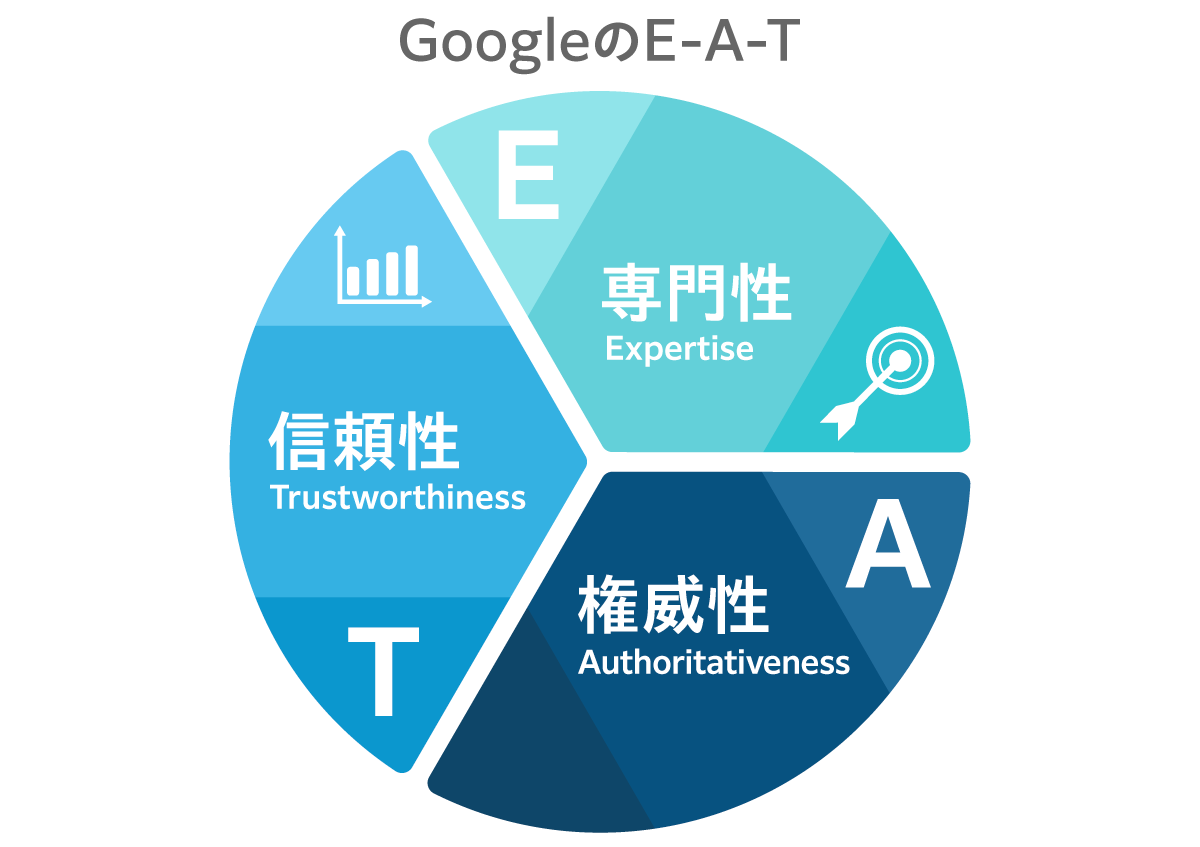
「高品質なコンテンツ」といったときに、具体的にそれは何かといえば、この3要素がそろっているコンテンツのことなのだ。
【E】専門性 | サイト運営者やその記事の執筆者に専門的なスキルや資格、経験があること。受賞歴、資格、人生経験など。 |
【A】権威性 | 社会的な承認を得ていること。その分野や業界で権威、第一人者として認められていること、他サイトからの多数の言及の獲得など。 |
【T】信頼性 | 企業概要や運営者情報などが公開され、身元が確かなこと。信頼性の高い文献を出典としていることなど。 |
詳しくは以下の記事を参考にしながら、コンテンツづくりに反映させてほしい。
3:ユーザビリティを高める
「キーワード選定も、コンテンツの質も、十分に努力しているのに、検索結果では競合ページに競り負けてしまう」
という場合、負けているのは「ユーザビリティ」かもしれない。
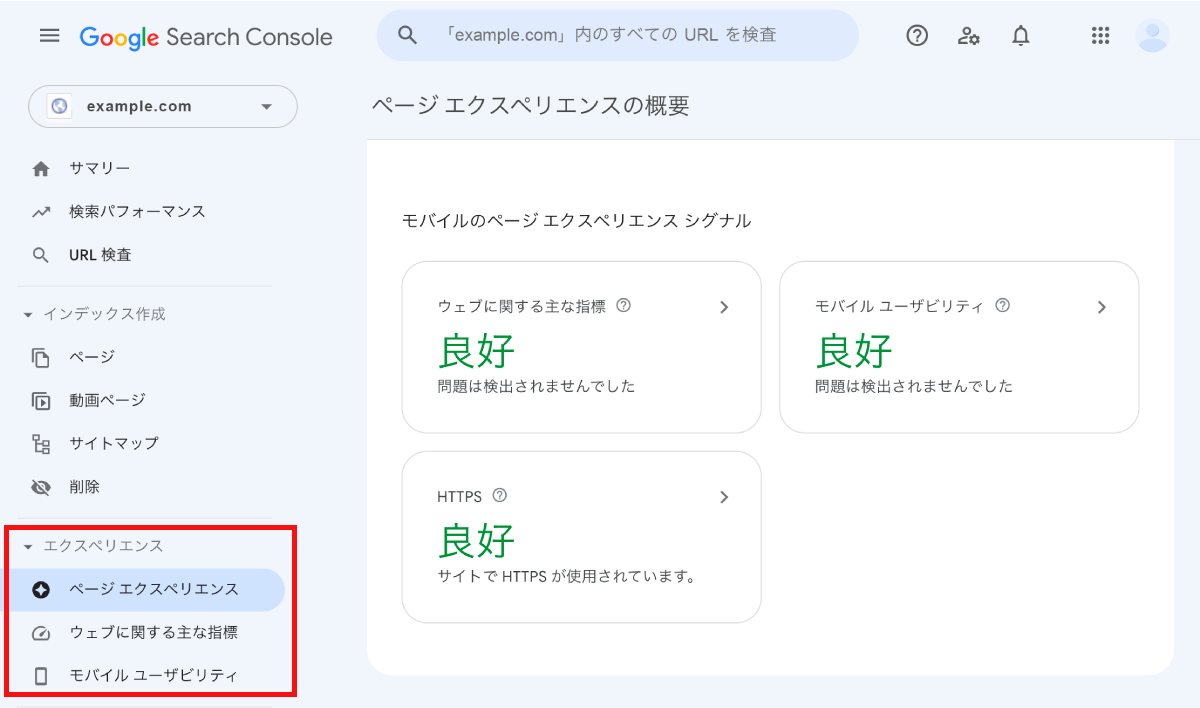
とくに、近年のGoogleは「ページエクスペリエンス」という概念をランキング要因として採用している。
Search Consoleのページエクスペリエンスにて、問題が検出されていないかチェックしておこう。
以下に参考ページをリストアップしておく。
5. もっと深く仕組みを知りたい人向けのマニアックな情報源
最後に、検索エンジンを作ってみたいプログラマや、圧倒的な知識量で競合を圧倒したいSEO専門家に、マニアックな情報源を2つ、ご紹介する。
5-1. Google創業者のラリーとセルゲイが書いた論文
検索エンジンの仕組みを技術的に知りたい人には、Google創業者のラリーとセルゲイが書いた論文、
『The Anatomy of a Large-Scale Hypertextual Web Search Engine
(大規模なハイパーテキスト型Web検索エンジンの仕組み)』
がおすすめである。
1998年の古い論文ではあるが、Googleの基礎がどのようにできているのか学ぶうえで、有益だ。以下のPDFより確認できる。
![]()
The anatomy of a large-scale hypertextual Web search engine
※英語で書かれているため、翻訳しながら読んでほしい。
5-2. 特許を取得している仕組み・アルゴリズム
Googleのアルゴリズムは公開はされていないが、一部の特許を取得しているアルゴリズムは、特許情報を確認することで、概要を把握できる。
米国の特許検索サイトから検索するか、Googleの特許検索ページからも、検索できる。
▼ 特許の例
● PageRank
● TrustRank
● Context Sensitive Ranking
● Agent rank
● Inferring Geographic Locations for Entities Appearing in Search Queries
● Presenting Social Search Results
Google以外にも、MicrosoftやYahoo!などが取得している特許もある。
参考:[Search Engine]で特許検索した検索結果ページ
マニアックな情報収集には、うってつけだ。
6. まとめ
本記事では「検索エンジンの仕組み」をテーマに解説した。要点を簡単にまとめておこう。
検索結果が表示されるまでの3つのプロセスは、以下のとおりだ。
- クロール:ボットが既知ページのリンクをたどって巡回しページの情報を収集する
- インデックス登録:Googleが必要と考えたページを選択してGoogleのデータベースに格納する
- 検索結果の表示:検索クエリとコンテンツを分析してユーザーにとってベストなURLリストを生成する
それぞれのプロセスに対して実践したいSEO対策として、以下を紹介した。
クロール |
|
インデックス登録 |
|
検索結果の表示 |
|
仕組みを知ったうえでSEOに取り組むと、意味もわからず聞いた作業をするより、ずっと楽しいはずだ。そして何より、結果が出る。
さっそく、積極的な姿勢でSEOを実践していこう。