robots.txtとは、Googleなどの検索エンジンのクローラーに対して、「どのURLにアクセスしていいか」を伝えるものである。
これを使えば、特定のページやフォルダのクロールを拒否できる(クロールさせない)ことができる。クローラーの動きを最適化することで、SEOの観点からも良い影響を得られる可能性がある。
robots.txt は こんなファイル |
User-agent: Googlebot |
「クロールさせないコンテンツ」を指定することで、重要なコンテンツを優先的にクロールさせることが可能となる。そのため、robots.txtには一定のSEO効果を期待できるといえるだろう。
しかしながら、robots.txtは、かならずしも設置しなければならないものではない。
Google公式ヘルプを確認すると、Googleは「大規模サイトや、更新頻度が高い中規模サイトでなければ、robots.txtは設置しなくても構わない」と書かれている。

この記事では、「robots.txtで何ができるのか」という基本的な情報はもちろん、「結局のところ設置した方が良いの?」「どんなページに設置すべきなの?」という疑問にしっかりと答えていこうと考えている。
robots.txtを設置しようとしている全てのコンテンツ担当者は、ぜひこの記事を読んで参考にしてほしい。


目次
- 1. robots.txtとは
- 2. robots.txtを設定する目的2つ
- 3. robots.txtの適切な設定はSEOに良い影響がある
- 4. robots.txtとnoindexタグとの違い
- 5. robots.txtを設置すべきか判断するポイント
- 6. robots.txtでクロール拒否する対象を選ぶ時のポイント
- 7. robots.txtの設定方法は3ステップ
- 8. 設定方法1:robots.txtのテキストファイルを作る
- 9. 設定方法2:robots.txtテスターで動作を確認する
- 10. 設定方法3:robots.txtファイルをFTPでアップロードする
- 11. robots.txtを設置する上での4つの注意点
- まとめ
1. robots.txtとは
robots.txtとは、サイトの一番上の階層に設置するテキストファイルのことで、サイト内の指定したURL(ページやフォルダ)をクロールしないよう指定するのが主な役割となる。
例えば、1万ページある大規模なサイトがある場合、全てのページにクローラーが巡回するのには時間がかかってしまう。すると、サイト内の重要なページがクロールされるのが遅くなる可能性がある。
このようなケースで、robots.txtで「クロールしなくて良いページ」を指定しておけば、重要ページを優先的にクロールしてくれるため、SEOの観点からサイト全体に良い影響があると考えられる。
小規模サイトなどでは問題なくクロールできるケースが多いが、特に大規模なサイトの場合には、robots.txtの適切な設定がSEO効果につながる可能性があるのだ。
※クロールとは、クローラーと呼ばれるロボットが世界中のWebページを巡回し、サイト情報を収集することをいう。
検索エンジンの仕組みをご存知ではない方は、検索エンジンの仕組みで解説しているのでまずはこちらを確認してほしい。






2. robots.txtを設定する目的2つ
robots.txtの主な目的については前述の通りだが、改めてここからはrobots.txtを設定する2つの目的について解説していこう。
2-1. 重要なコンテンツを優先的にクロールしてもらえる
robots.txtを設定するメインの目的は、指定したページやフォルダをクロールさせないようにして、クローラーの動きを最適化させることである。
クローラーは、蜘蛛の巣のように張り巡らされたリンクをたどって巡回する蜘蛛のようなものだ。しかしながら、クローラーできる容量にも限界がある。
何万ページもあるようなサイトの場合、自動生成ページなどを含む全ページをクロールさせてしまうと、本当に大事なコンテンツのクロールが遅くなってしまう可能性があるのだ。
そこでrobots.txtを使い、優先度の低いページやフォルダをクロール拒否しておくことで、優先的にクロールしてほしいコンテンツを確実にクロールさせることができる。
その結果として、サイト全体が適切な評価を受けやすくなり、SEOにも良い影響がある。
2-2. メディアファイルを検索結果に表示できなくできる
robots.txtを設定することで、メディアファイル(画像・動画・音声ファイル)を検索結果に表示できなくすることが可能だ。
HTMLファイルの場合は、metaタグで「noindex」を設定すれば検索結果に表示させないことが可能だが、画像・動画・音声ファイルにはタグを書く場所がないため「noindex」は使えない。
そのため、robots.txtに記述して検索結果に表示できなくさせる方法を採るしかない。
// サイトの直下にある「images」というフォルダをクロール拒否にしたい場合 |
ただし、既にインデックスされてしまっている場合にはこの方法は使えないので注意しよう。
3. robots.txtの適切な設定はSEOに良い影響がある
前述した通り、robots.txtでクローラーの動きを最適化することで、サイトの重要なコンテンツをより効率的に巡回できるようになるため、SEOにとっては良い影響があると考えられる。
ただし、それほど大規模なサイトではない限り、「robots.txtを設定するだけで、検索順位大幅に上がった!」のような大きなSEO改善効果があるものではない。
Googleは、「クロールの割り当てとは、ほとんどのパブリッシャーの方々にとって気にすべきものではない」と言っているからだ。「サイトのURLが数千もない場合、そのサイトのクロールはたいてい効率的に行われる」というのがその背景だ。
参照:Google検索セントラル/Googlebot のクロールの割り当てについて
つまり、よほどページ数が多いサイトでない限り、robots.txtの対策をしたからといって劇的に順位が上がるようなSEO対策とは言えない点には注意しよう。
4. robots.txtとnoindexタグとの違い
robots.txtと似ているものに「noindexタグ」があるが、役割が違うので整理しておこう。
大きな違いは、robots.txtはクロール(巡回)をブロックするもので、noindexタグはインデックスをブロックするものであるという点だ。
| robots.txt | noindexタグ |
| クロール(巡回)をブロックするように制御するもの | インデックスをブロックするように制御するもの |
| インデックスは削除はできないので注意 | インデックス済コンテンツのインデックスから削除できる |
インデックスとは、以下の「Googleの検索結果に表示されるまでの流れ」の2番目に該当する部分であり、検索エンジンにページが登録されることを意味している。
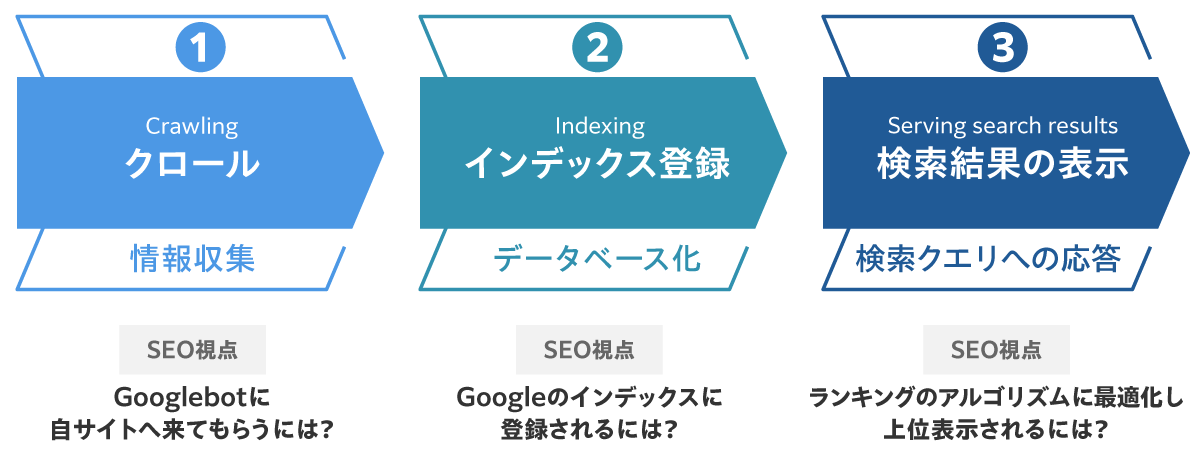
つまり、robots.txtは上記の「①クロール」をさせないための指示、noindexタグは上記の「②インデックス登録」をさせないための指示といえる。
robots.txtで指定したページやフォルダは、クローラーが巡回しなくなる。しかし、クロールされなくても、既にクロールされていたり他のページからリンクを貼られたりしていれば、インデックスされる可能性はある。
つまり、インデックスされたくない場合は、robots.txtではなくnoindexを使うべきだ。
noindexを指定する場合は、ページごとのmeta要素に記述することで制御できる。詳しくは、バズ部の別記事「noindexとは?設定方法や注意点を分かりやすく解説」を確認してほしい。
5. robots.txtを設置すべきか判断するポイント
「結局のところrobots.txtは設置した方が良いの?」と疑問に思う方も多いだろう。
結論から言うと「robots.txt」の設置は必須ではなく、Google公式ヘルプでも「大規模なサイト所有者向けのクロール バジェット管理ガイド」として紹介されているものである。
Google公式ヘルプには、「サイトの URL が数千もない場合、そのサイトのクロールはたいてい効率的に行われます」と書かれており、小規模サイトがrobotx.txtを置かないことには問題はない。
5-1.【大前提】robots.txtは設置しなくても良い
robots.txtは、何度も言うようにクロール許可をブロックするために設置するものである。
クロール拒否したいコンテンツが特に無い場合は、設置しなくて全く問題ない。
ウェブサイトにrobots.txtファイルは必要ですか? いいえ。Googlebotがウェブサイトにアクセスする際、まずrobots.txtファイルの取得を試みることによって、クロールの許可を求めます。robots.txtファイルの取得を試みることによって、クロールの許可を求めます。robots.txtファイルのないウェブサイトでは、通常、robotsメタタグまたはx-Robots-Tag HTTPヘッダーがクロールされ、問題なくインデックスに登録されます。 |
参考:Google検索セントラル「robotsに関する一般的な質問」
5-2. 中規模(1万ページ)以上のサイトはrobots.txt設置がおすすめ
Google公式ヘルプによると、クロール割り当ての対象者を以下のように説明している。
クロール割り当てを推奨する対象者 |
❶大規模(重複のないページが 100 万以上)で、コンテンツが中程度に(1 週間に 1 回)更新されるサイト |
参考:Google検索セントラル>大規模なサイト所有者向けのクロール割り当て管理ガイド
大規模サイト(100万ページ以上)や更新頻度が高い中規模サイト(1万ページ以上)では、Googlebotが一度にクロールできる能力を超えてしまい、正しくインデックスされない可能性がある。
あなたの運営サイトが1万ページ以上の規模のサイトなら、robots.txtを設置し、サイトのクロール効率を最大化すべきである。
どのコンテンツをクロール拒否すればいいかを決める時には、Googleヘルプに書かれている内容を参考にしよう。できるだけ重要度が低いコンテンツから順番に、robots.txtの「Disallow」でクロールを拒否する設定を行おう。
※他サイトから参照している場合、robots.txtでクロール拒否してもクロールなしでインデックスされる可能性がある。インデックスされたくない(検索結果に表示されたくない)場合には、robots.txtではなく「noindex」を使おう。
5-3. 小規模サイトや更新頻度が低いサイトはrobots.txtがなくても良い
3-2で解説した条件に合致していない小規模サイトや更新頻度が低いサイトの場合は、robots.txtそのものを設置しなくても、クロール上の問題は起こらない。
では、SEOの観点からはどうだろうか?
robots.txtを置くことで重要なコンテンツのクロールが優先されてSEO効果を得られるのは、Googleボットのクロールが間に合わないような中~大規模サイトに限定される。
小規模サイトであればrobots.txtが無くても正しくクロールされるため、robots.txtでクロール拒否したからといって劇的なSEO効果が得られる可能性は低い。
ただし、SEO効果はなくとも、明らかにクローラーにとって意味のないページやディレクトリは、クロール拒否を指定しておいても良いだろう。
5-4. メディアファイルをインデックス拒否する時はrobots.txtを設置すべき
サイトの規模によらず、メディアファイル(画像・動画・音声ファイル)をGoogle検索結果に表示させたくない場合には、robots.txtを設置すべきである。
「2-2. メディアファイルを検索結果に表示できなくする」で述べた通り、robots.txtでしかメディアファイルをGoogle上で非表示にする方法は無いからである。
5-5. Search Consoleで多くのページがエラーになる場合もrobots.txtを設置すべき
「Search Console」で合計URLの大部分が「検出- インデックス未登録」に分類されてしまう場合には、robots.txtを設置すべきである。
クロール上の問題が起きている可能性があるため、robots.txtを設置して、クロールしてほしいコンテンツを優先的にクロールさせる必要がある。
6. robots.txtでクロール拒否する対象を選ぶ時のポイント
大規模サイトなどでrobots.txtでクロール拒否してクローラーの動きを最適化したい場合、どのページを拒否すべきか迷うことがあるだろう。
そのような場合は、以下のような2つのページをまず優先的に設定すると良いだろう。
・プログラムによる自動生成コンテンツ
・広告リンク先ページ
くわしく説明していく。
6-1. プログラムによる自動生成コンテンツ
robots.txtでクロール拒否すべきページの代表として挙げられるのが、プログラムによる自動生成コンテンツである。
基本的には、検索エンジンやユーザーにとって価値のないページに対するクロールは、robots.txtでブロックするという考えがベースとなる。
自動生成ページは、ある特定のユーザーには意味があっても、その他のユーザーや検索エンジンにとっては価値がないページであることが多い。
そのため、大規模サイトで「どのコンテンツをブロック拒否しよう?」と考えた時に、自動生成コンテンツがまずは候補になるだろう。
繰り返しになるが、ユーザーにとって価値のないページに対するクロールはブロックするのがおすすめだ。価値がないページかどうか判断が難しい場合には、Googleのいう「質の高いサイト」の28の項目を満たしているか確認しよう。
注:自動生成ページと重複コンテンツについて 「自動生成ページ」と「重複コンテンツ」を同一と考えている方が多いが、それぞれ別物であり対策方法も違う。 例えば、Googleは重複コンテンツに対するクローラーの巡回をrobots.txtで禁止することはおすすめしないと言い切っている。(参照:『重複するコンテンツ』) 簡単に言うと、自動生成ページはrobots.txtでクロールをブロックし、重複コンテンツはcanonicalの使用が推奨されている。詳しくはcanonicalの使い方を参考にしてほしい。 |
6-2. 広告リンク先ページ
robots.txtでクロール拒否すべきページのもうひとつが、広告リンク先ページである。
これは広告ASPを運用している会社やプレスリリースの配信会社が行うべきものであり、ほとんどのサイト運営者にとっては行う必要がないことなのだが念のために解説しておく。
Googleは単なる広告を良質なコンテンツとは考えておらず、広告にクローラーが回り検索順位に影響を与えることを歓迎していない。
そのため、広告ページに対するリンクは、そのページ対する直リンクではなく以下のようになっていなければならない。※さらにサイトから広告ページに対するリンクには、「rel=”nofollow”」がついている必要がある。

Google Adsense 広告や広告ASPが発行するリンクはこのように自動的に、robots.txtでクロールをブロックしているリダイレクトページが挟まれるものになっている。
しかし、もしこのような仕組みになっていない広告ASPを使うと、最悪の場合、あなたのサイトも、広告ページもペナルティを受ける可能性がある。
もしあなたがアフィリエイト広告の掲載、もしくは出稿を考えているなら事前に必ず確認する事をお勧めする。
7. robots.txtの設定方法は3ステップ
ここからは、実際にrobots.txtを設定する場合の方法について解説していこう。
robots.txtをサイトに設置する方法には、以下の3ステップがある。

それぞれの工程の詳しいやり方について、8章から10章までで解説していく。
8. 設定方法1:robots.txtのテキストファイルを作る
robots.txtをサイトに設定するための最初のステップは、テキストファイル(.txt)を作ることだ。
具体的には、「メモ帳」などのテキストエディタに直接以下のような内容を書いていけば良い。
User-agent: Googlebot |
robots.txtは4つの要素(User-Agent、Disallow、Allow、Sitemap)からなる。
それぞれの要素ごとに、詳しい書き方と記述例を紹介していこう。
8-1. User-Agent
どのクローラーの動きを制御するかを指定する部分。続けて「Disallow」または「Allow」を設定しよう。
// Googleのクローラーを対象にして、特定のフォルダをクロール拒否したい場合 |
特にこだわりが無ければ「*」としておけば、Google含むすべてのクローラーを指定できる。
// 全てのクローラーを対象に、特定のフォルダをクロール拒否したい場合 |
命令文を組み合わせて、記述することもできる。
// Googleのクローラーには特定のフォルダをクロール拒否にして、その他のクローラーには全体のクロールを許可する場合 |
より細かい設定を行いたい場合は、以下のサイトを参考にしよう。
Googleのクローラー一覧:「Googleのクローラ(ユーザーエージェント)」
その他クローラー一覧:「クローラ(ロボット)のユーザーエージェント(UA)一覧」
8-2. Disallow
特定のファイルやフォルダをここに指定することで、クロールしないよう命令できる。
// サイトの直下にある「sample」というフォルダをクロール拒否にしたい場合 |
パターンが多いので順番に紹介していく。
サイト全体のブロック:スラッシュのみ
Disallow: / |
特定のディレクトリとその中身を全てブロック:ディレクトリ名の後にスラッシュを入力
Disallow: /junk-directory/ |
特定のページをブロック:ブロックしたいページを指定
Disallow: /private_file.html |
特定のファイル形式(例:.gifファイル)をブロック:以下の記法で指定
Disallow: /*.gif$ |
特定の文字列(例:?)を含む全てのURLをブロック:以下の記法で指定
Disallow: /*? |
より豊富な実例は、Google検索セントラル「Google による robots.txt の指定の解釈」を参考にしてほしい。
8-3. Allow
Disallowでクロールさせない設定にしているフォルダの中で、例外的にクロールさせたいファイルやフォルダを指定すると、クロールを許可できる。
// wp-adminフォルダはクロール拒否するが、例外的にphpファイルはクロールしてもらいたい場合 |
例外的にクロールさせたいページを指定する命令文なので、クロール拒否するページがない場合には使用しなくて問題ない。
8-4. Sitemap
サイトマップ(sitemap.xml)の場所をクローラーに伝えることで、クローラーに正しくクロールしてもらうことを促せる。設定は必須ではないが、設定しておくのがおすすめである。
Sitemap:http://sample-site.jp/sitemap.xml |
他の要素と違ってサイトマップは「絶対アドレス」の指定が必須なので、必ず「http」や「https」を含むアドレスをここに指定しよう。
9. 設定方法2:robots.txtテスターで動作を確認する
robots.txtをサーバーに上げる前には、対象となるページだけが制御されるかどうかを必ず確認しよう。
Googleサーチコンソール内から、robots.txtのテスト用ツール「robots.txtテスター」が利用できる。
アクセスすると、以下の様な画面が開く。
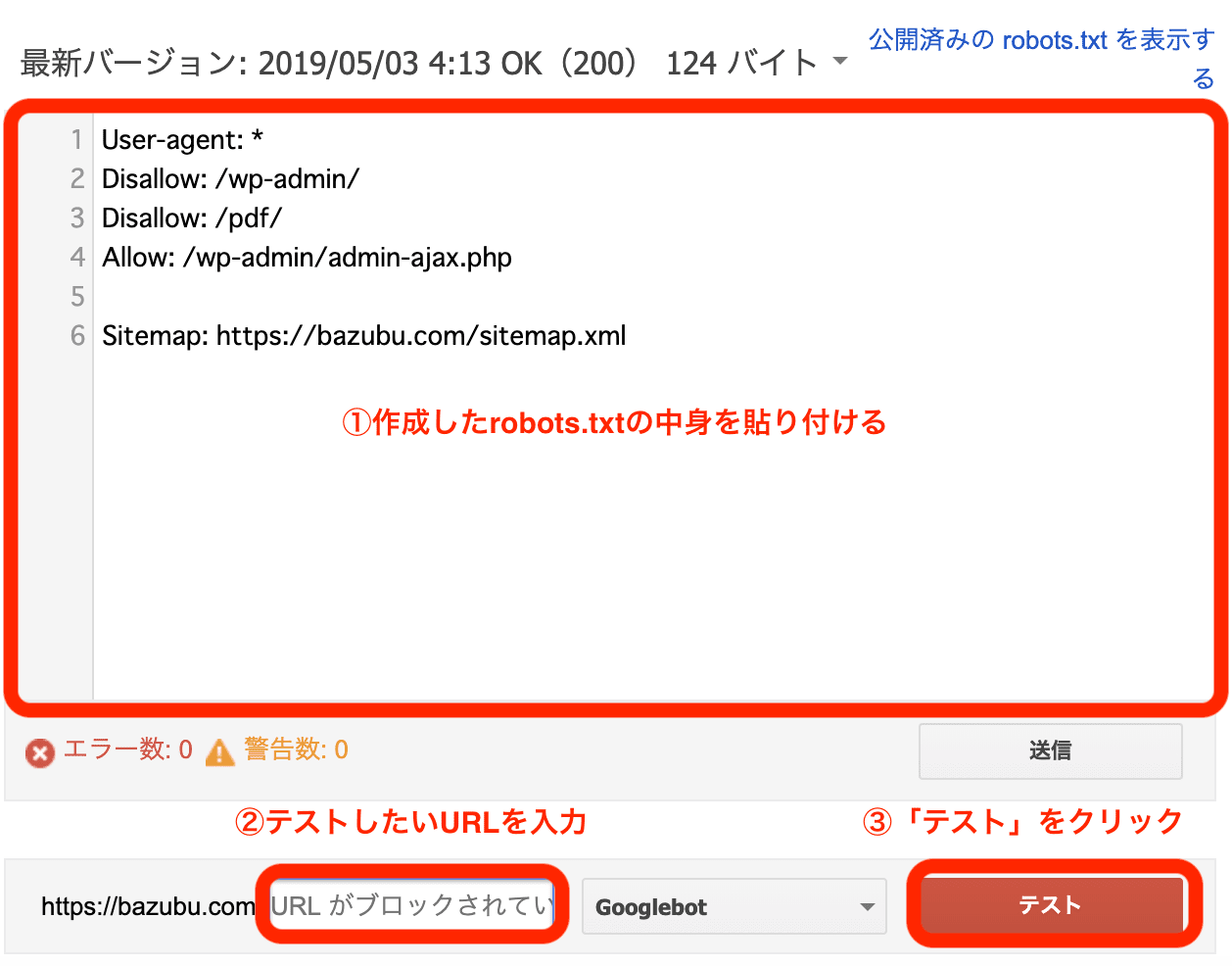
手順は以下である。
❶robots.txtテスターを起動して、プロパティ(設置するサイト)を選択する
❷入力欄が表示されるので、作成したrobots.txtの内容をコピーして貼り付ける
例 |
❸クロール拒否したいページ(例の場合は「wp-admin」フォルダ)を下の入力欄に入れて、テストボタンを押す
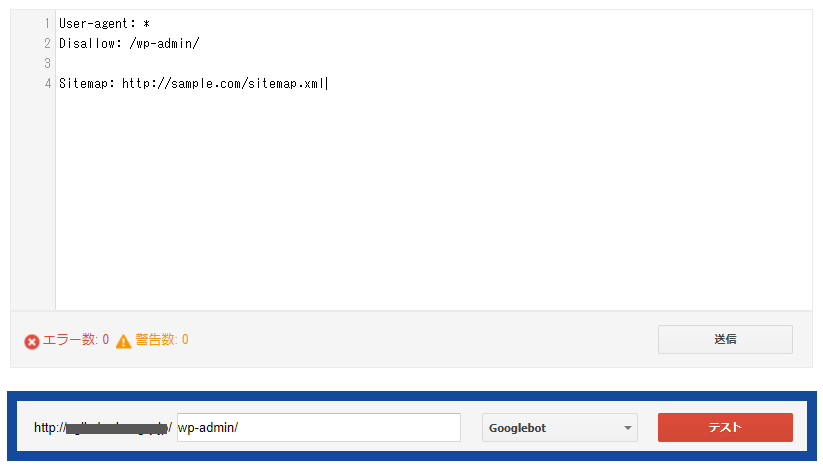
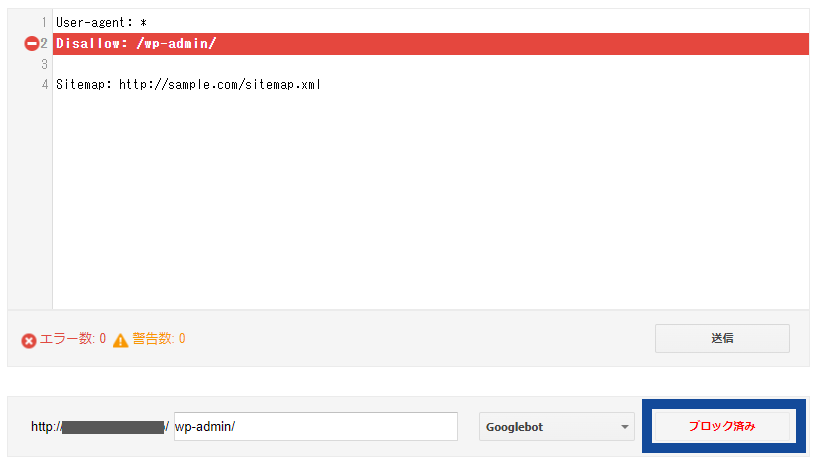
❹「ブロック済み」と表示が変われば、正しく記述できていると確認できる
❺同様に、例外的にクロールを許可したいページ(例の場合は「wp-admin/admin-ajax.php」ファイル)が許可されていることも確認できる。
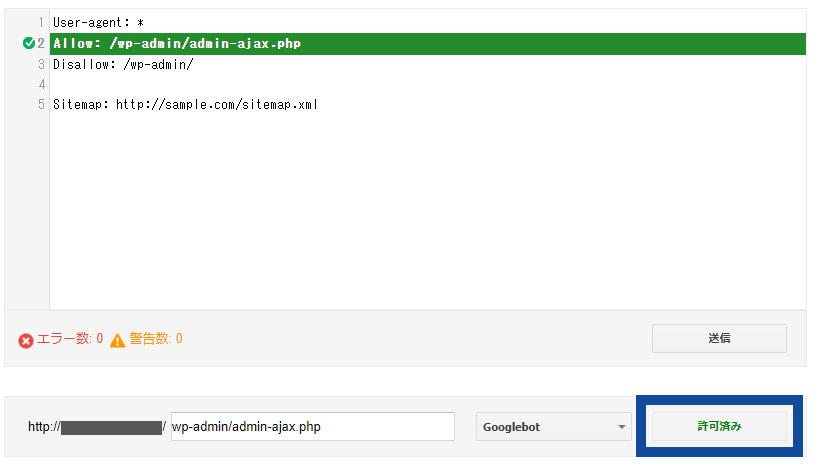
※ここで「送信」ボタンを押すと、ここからrobots.txtを更新することも可能である。
誤って重要なページのクロール制御を行ってしまうと大問題になりかねない。必ずアップロード前にテストを行っておこう。
10. 設定方法3:robots.txtファイルをFTPでアップロードする
最後に、作成したrobots.txtファイルを、FTPソフトを使ってルートディレクトリにアップロードしよう。
ルートディレクトリとは、サイトが保存されているアドレスの直下のことである。ルートディレクトリ以外に置いてしまうと正しく制御できないので注意しよう。
例えばサイトのアドレスが「http://sample.com/」の場合、以下の場所にrobots.txtファイルを置くのが正解となる。
正解:http://sample.com/robots.txt |
なお、サブディレクトリ型のサイトなど、ルートディレクトリにrobots.txtを配置できないケースでは、ページごとにメタタグによる指定が必要となるので注意しよう。
// メタタグの例(各ページのヘッダー部分に記述する) |
アップロードできたら、robots/txtの設置作業は完了となる。
念のためアップロードした場所のURLをブラウザに打ち込んで、問題なく設置できているか確認してみよう。
11. robots.txtを設置する上での4つの注意点
最後に、robots.txtを設置する時に気を付けたい注意点を4つ解説する。使い方を間違ってしまうとSEOにおいて逆効果になることがあるため注意しよう。
11-1. SEOでマイナスにならないよう慎重に設定しよう
ここまで解説したように、robots.txtはクロールさせたくないコンテンツをクロール拒否できる便利な仕組みである。
しかしむやみやたらにクロールさせてたり間違って指定してしまったりすると、本来クロールすべきコンテンツを巡回してもらえなくなり、SEOにおいてマイナスになりかねない。
例えば、間違って以下のように設定してしまうと、全ページがクロール拒否になってしまう。
例 |
こうしたミスが起こらないよう、慎重に設定するようにしよう。
11-2. robots.txtを指定してもインデックスはされる
robots.txtの設定でクロール拒否しても、他ページからリンクされていれば、クロールすることなしにインデックス登録されてしまう可能性がある。
Google検索結果に表示されないようにしたければ、robots.txtを使うのではなく、noindexタグを使うかパスワード保護など別の方法を使おう。
// noindexタグを使う場合 |
noindexについては、「noindexとは?設定方法や注意点を分かりやすく解説」の記事でさらに詳しく解説しているので参照してほしい。
11-3. 既にインデックスされているページは検索エンジンに残る
11-2の内容とも関連するが、既にインデックスされているページは、新しくrobots.txtでクロール拒否の指示を出したところで検索エンジンに残ってしまう。なぜならば、すでにインデックスされてしまっているからだ。
インデックスされてしまったページのインデックスを拒否するには、一旦robots.txtの指定を外してクロールできる状態にしてからnoindexタグを設定する必要がある。その後、インデックス削除されたことを確認してから、またrobots.txtを設定する。
インデックスされてしまったページのインデックス登録を削除する方法 |
❶robots.txtの指定を外してクロール可能にする |
少し手間はかかるが、これでインデックス済みのページを検索エンジンから排除できるので覚えておこう。
11-4. robots.txtで制御できない検索エンジンもある
Googlebotなど主要なクローラーはクロール前にまずrobots.txtを確認し、ブロックされているページがあるかどうかを確認する。
しかし、Google以外の検索エンジンも全てrobots.txtに対応しているとは限らない。
そのため、全ての検索エンジンから隠したいページがあるならば、robots.txtではなく、ページをパスワードで保護するなど別の方法を利用するのがおすすめである。
まとめ
本記事では「robots.txt」をテーマに解説した。要点を簡単にまとめて終わりにしよう。
最初に、robots.txtとは何かについて、以下の事柄を解説した。
・robots.txtとは、サイトの一番上の階層に設置するテキストファイルのこと |
robots.txtを設定する目的には、以下の2つがある。
・クローラーの動きを最適化する |
robots.txtを適切に設定することで、SEOに良い影響がある。
しかし、小規模サイトであれば、robots.txtを設置しなくても正常にクロールできるケースがあるため、設置は必須ではない。
robots.txtを設置すべきか判断するポイントとしては、以下を参考にしてほしい。
・【大前提】robots.txtは設置しなくても良い |
robots.txtはサイト内部対策のほんの一つにすぎないが、あなたが作った良質なコンテンツを検索エンジンに正しく評価してもらう上では必要不可欠な機能だ。
あなたのサイトをより最適化する為にも、robots.txtを利用する事をお勧めする。また他の内部対策一覧は「SEO内部対策チェックリスト」で紹介しているので、ぜひ参考にしてみてほしい。