SEOにおけるインデックスとは、簡単にいえば、Googleの大規模なデータベースのことで、Googleのロボットが世界中のWebページから収集したテキスト、画像、動画などを解析した情報が格納されている。
Googleの検索結果に表示されるためには、インデックスされることが不可欠だ。SEOにおいてインデックスを正しく理解することは非常に重要である。
にもかかわらず、インデックスについて曖昧な理解のままSEOを行っている人も多く、失敗原因となっている。
本記事では、これからSEOに初めて取り組む人に向けて、最初に知っておくべきインデックスの重要知識をまとめた。
「インデックスされない」と悩んだときも、「インデックス登録を戦略的に進めたい」とレベルアップを目指すときも、本記事が役立つ。ぜひ、手元において参考にしてほしい。


目次
1. SEOの「インデックス」とは?基本の知識
最初にインデックスとは何か、基本の知識から見ていこう。
1-1. インデックスとは索引のこと
インデックス(index)とは「索引、見出し」という意味だ。
SEOにおいては、検索エンジンのデータベースの検索速度を向上させるために作成される索引を指す。
検索エンジンでは、インデックスに登録されたWebページから、検索キーワードにあわせて適切な検索結果を返してくれる仕組みになっている。
1-2. “インデックスされる”とは?
よく「インデックスされる」という表現をする。
厳密な意味としては「Googleのデータベースの索引に登録される」という意味になるが、実際には“Googleのデータベースに保存される”ことを「インデックス登録」と呼んでいる。
Googleの公式サイトでも、
「Googleインデックス(大規模なデータベース)に保存」
という表現が使われている。

SEOの実務上「インデックスされる」という言葉を使うときには、
「WebページがGoogleのデータベースに登録され、ユーザーが検索したとき、検索結果にそのWebページが表示できる状態になる」
という意味と捉えておけば問題ない。
1-3. インデックス登録=Googleのお墨付きではない
初めて自分のWebサイトやブログを立ち上げたばかりの人のなかには、インデックスされたことで、
「Googleの登録審査に通った。お墨付きをもらった」
と喜んでいるケースがあるが、これは誤解である。
先ほど「検索結果にそのWebページが表示できる状態になる」という表現を使ったが、“インデックスされること”と、“Googleから評価されて検索結果に表示されること”は、別の話だからだ。
具体的にどんな流れになっているのか、次の章で整理しておこう。






2. クロール・インデックス登録・検索結果の表示までの流れ
 Googleの検索には、3つのステージがある。
Googleの検索には、3つのステージがある。

「すべてのページが各ステージを完了できるわけではありません」と注意書きがあるとおり、3つのステージを完了して初めて、検索結果に表示される。
それぞれ解説する。
2-1. クロール
1つめのステージは「クロール」だ。
Googleは「クローラー」と呼ばれるソフトウェア(ロボットと呼んでもよい)を使用して、インターネット上を自動的に探索している。
クロール(crawl)というと泳法のクロールが思い浮かぶかもしれない。SEO用語としてのクロールは、クローラーが巡回することを指す。
たとえば「クローラーがきた」「クロールされた」というときは、クローラーからWebページにアクセスがあった、ということだ。
クローラーの仕事は、新しいページやコンテンツ(テキスト、画像、動画)を発見すること、発見したコンテンツを収集する(ダウンロードする)ことである。
ちなみにGoogleのクローラーは「Googlebot」と名前がついている。
クローラーはリンクをたどってやってくる
クローラーについて覚えておきたいのは、
「クローラーは過去にクロールしたことがある既知のページ内に設置されているリンクをたどってやってくる」
という点だ。
どこからもリンクされておらず、孤立しているWebページには、クローラーはたどり着けない。
早くクローラーに来てもらいたいなら、すでにインデックスされているページからリンクすることが重要になる。
2-2. インデックス登録
2つめのステージは「インデックス登録」だ。
クローラーがダウンロードしたコンテンツ(テキスト、画像、動画)を解析し、その情報をインデックスへデータベース化する。
データベース化とは、収集したデータを決められたルールに則って整理し、後から活用しやすくすることだ。
具体的に使われる情報としては、以下が挙げられる。
|
「どうインデックス登録されるか」がSEOの肝
若干脱線するが、ひとつ大切なことをお伝えしたい。
本記事ではSEO初心者の方のために初歩的な知識から解説したいので、今回は深掘りはしないが、将来のために覚えておいてほしいことがある。
インデックス登録は、“されるか/されないか”ではなく、“どう”されるか?が重要、ということだ。
これが、あらゆるSEOが目指す最終到着地といっても過言ではない。
「あなたのWebサイトのデータが収集されたあと、Googleのデータベースのどこにしまわれるか?」
とイメージしてみてほしい。
たとえば、
|
インデックス登録に限った話ではないのだが、Googleの挙動をただ知識として覚えるSEO担当者は伸びない。
「それって、どういうことなのか?」
と、自分で解釈して肚落ちさせていくと、その理解が、のちのち高品質なコンテンツの細部となって活きてくる。
2-3. 検索結果の表示
話は戻って、3つめのステージは「検索結果の表示」だ。
ユーザーがGoogleの検索窓にキーワードを入力すると、Googleはインデックス内から一致するページを探しにいく。
発見されたページの中から、
「関連性が高くて、高品質だ!」
とGoogleが「判断」したページが、検索結果に表示される。
インデックスにどう登録されているかによって「判断」が変わってくる、というわけだ。
3. インデックスに登録されているか確認する方法
「自サイトのページがインデックスに登録されているのか、確認したい」というときには、大きく分けて2つの確認方法がある。
3-1. Googleで検索
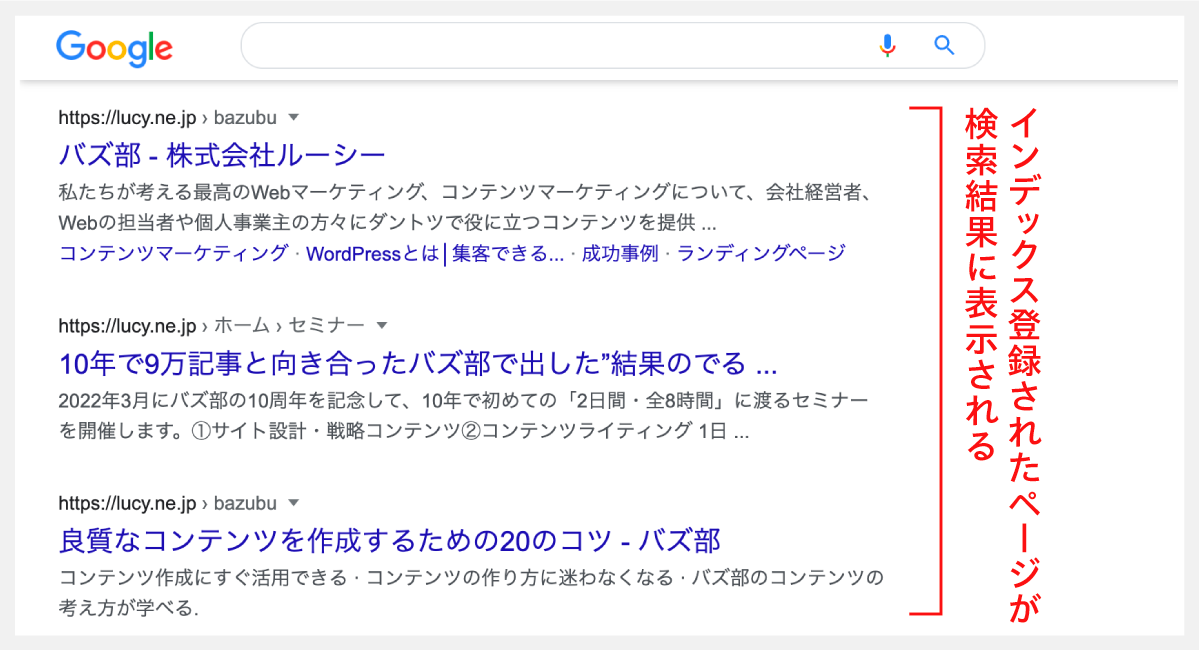
1つめの方法は、シンプルにGoogleで検索することだ。
「Googleの検索結果に表示される=インデックス登録済」という証となる。
自動フィルタリングを無効にする
注意したいのは、インデックスに登録されていても、検索結果に表示されるとは限らないことだ。
まずは、検索結果として合致するページが、自サイトのページしかなさそうな特異なキーワード(記事タイトルや、本文中のテキストを100文字程度コピーして検索するなど)で検索してみよう。
それでもヒットしないときには、自動フィルタリングを無効にして再検索する。
自動フィルタリングとは、類似ページを検索結果から除外する機能で、検索結果の最後尾に表示される「ここから再検索してください」をクリックすると、無効にして再検索できる。
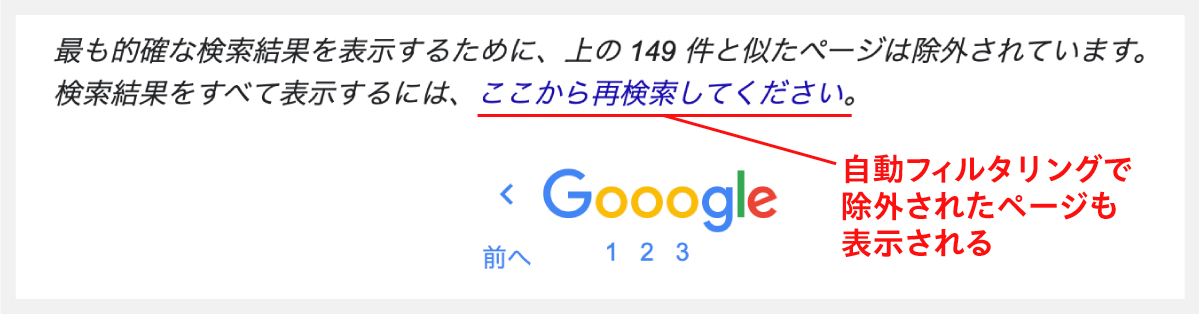
※補足:同じ挙動は検索結果のURLに「&filter=0」のパラメータを付与することでも得られる。
検索演算子でサイト検索する
サイト全体で登録されているページを確認したい場合は、サイトまたはドメインの前に「site:」をつける検索演算子で、サイトを絞って検索可能だ。
たとえば、このバズ部が掲載されているドメイン内を検索すると以下のとおりとなる。
| site:lucy.ne.jp |
※「検索演算子って何?」という方は、Googleヘルプの「ウェブ検索の精度を高める」にて確認しよう。
3-2. Search Consoleで確認
もうひとつの方法はGoogle Search Console(サーチコンソール)を利用するやり方だ。
※Search Consoleは「Google 検索結果でのサイトの掲載順位を監視、管理、改善するのに役立つGoogleの無料サービス」で、SEOには必須のツールである。
まだ導入していない方はGoogleヘルプの「Search Console の概要」から概要をチェックしよう。
サイト全体は「カバレッジ」
具体的な手順は、まずサイト全体のインデックス状況を見るためには、Search Consoleの管理画面のメニューから[インデックス]→[カバレッジ]にアクセスする。
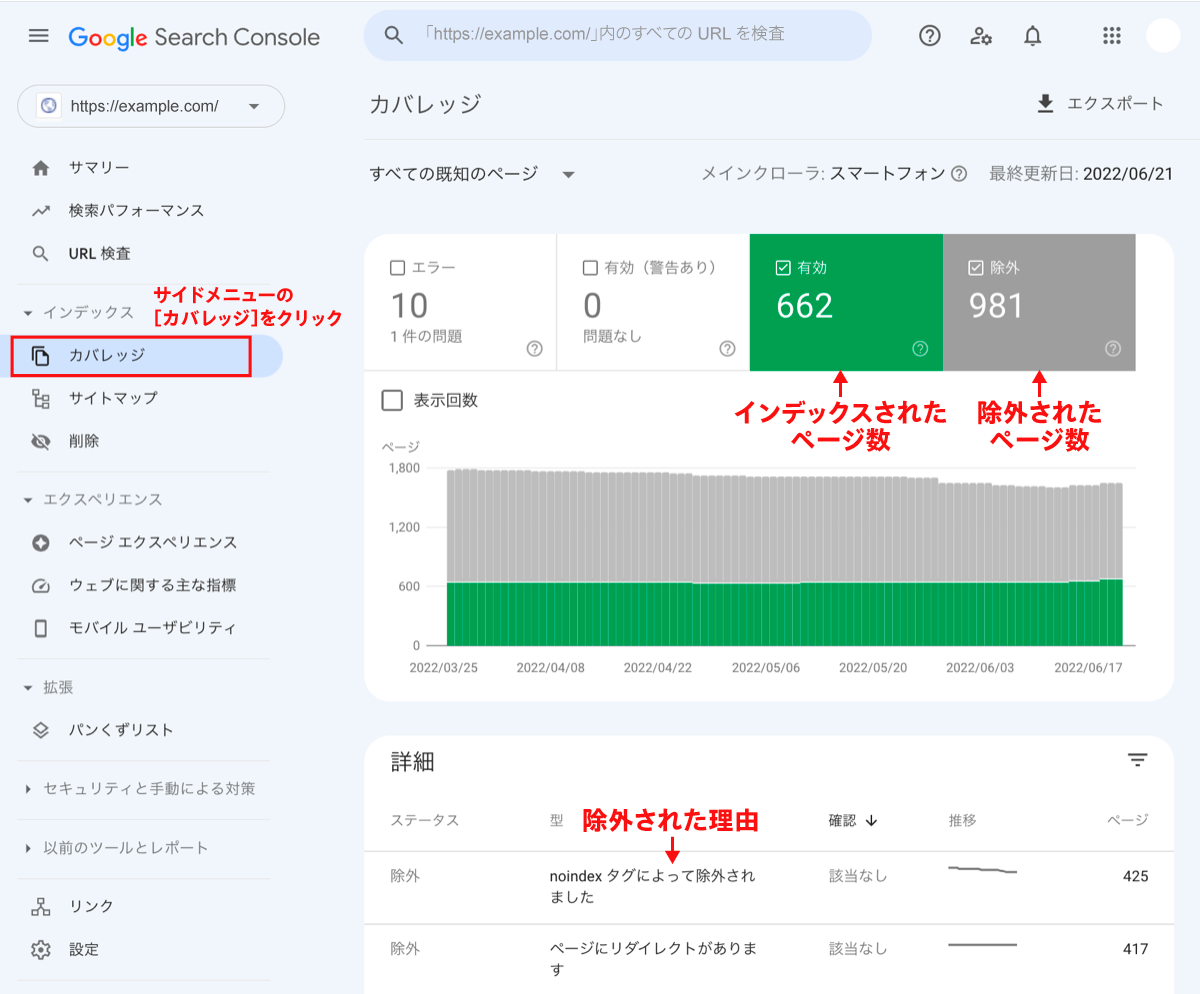
「有効」はインデックスされたページ、「除外」はクロールしたがインデックスからは除外されたページだ。
なぜ除外されたのか、その理由は下段[詳細]欄にて確認できる。たとえば上記では「noindex タグによって除外されました」「ページにリダイレクトがあります」と記載されている。
※noindex タグについては、後ほど「5. インデックス登録を「不許可」にする設定」にて解説する。
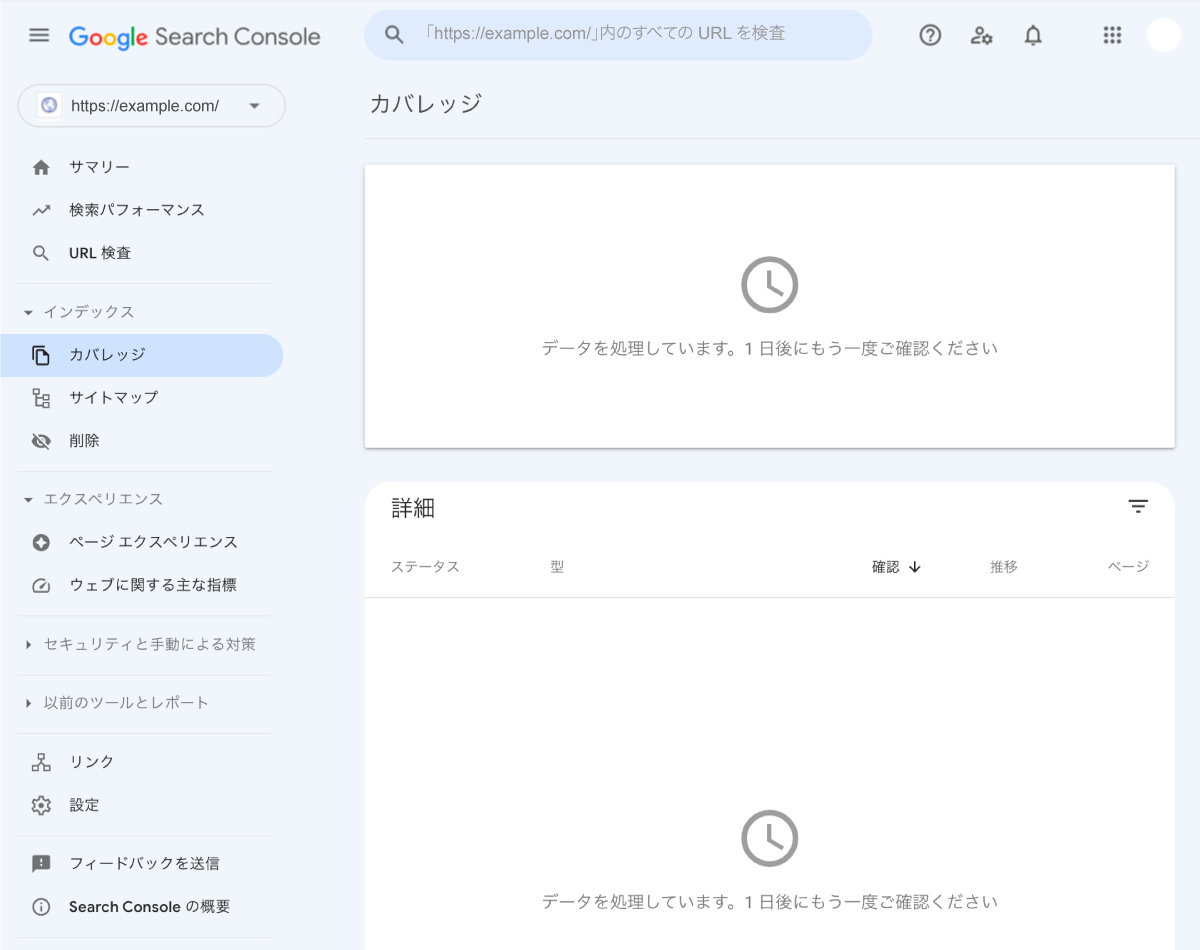
ちなみに、まだサイト内で1ページもクロールもされていないとき(ドメイン取得直後など)には、以下のような表示になる。
特定URLは「URL検査」
特定のURLがインデックスされたか知りたいときには、[URL検査]にて確認したいURLを入力する。
▼ インデックスに登録されているときのメッセージ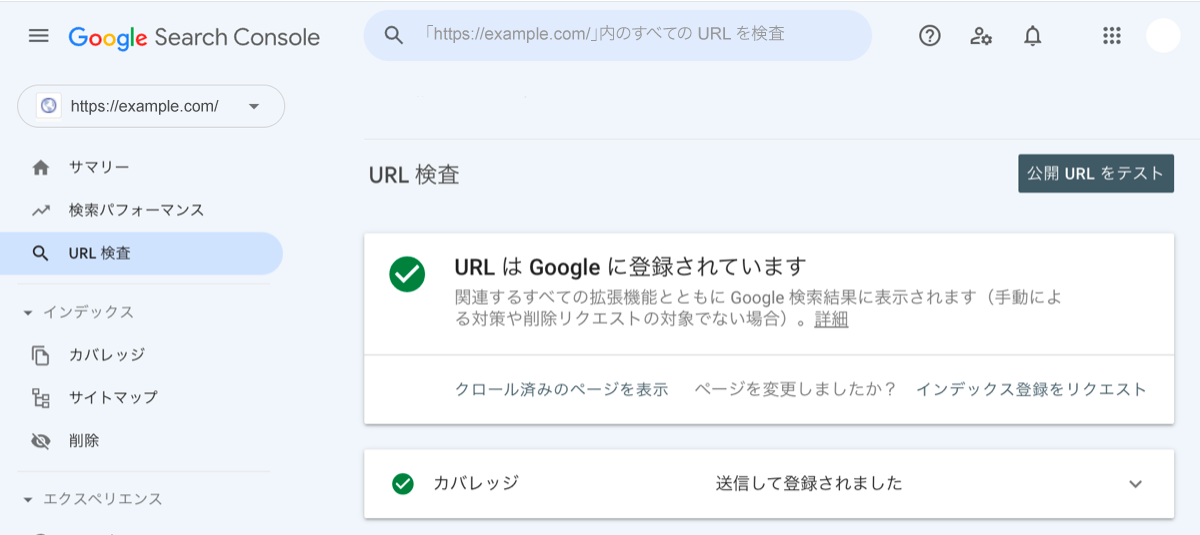
▼ インデックスに登録されていないときのメッセージ
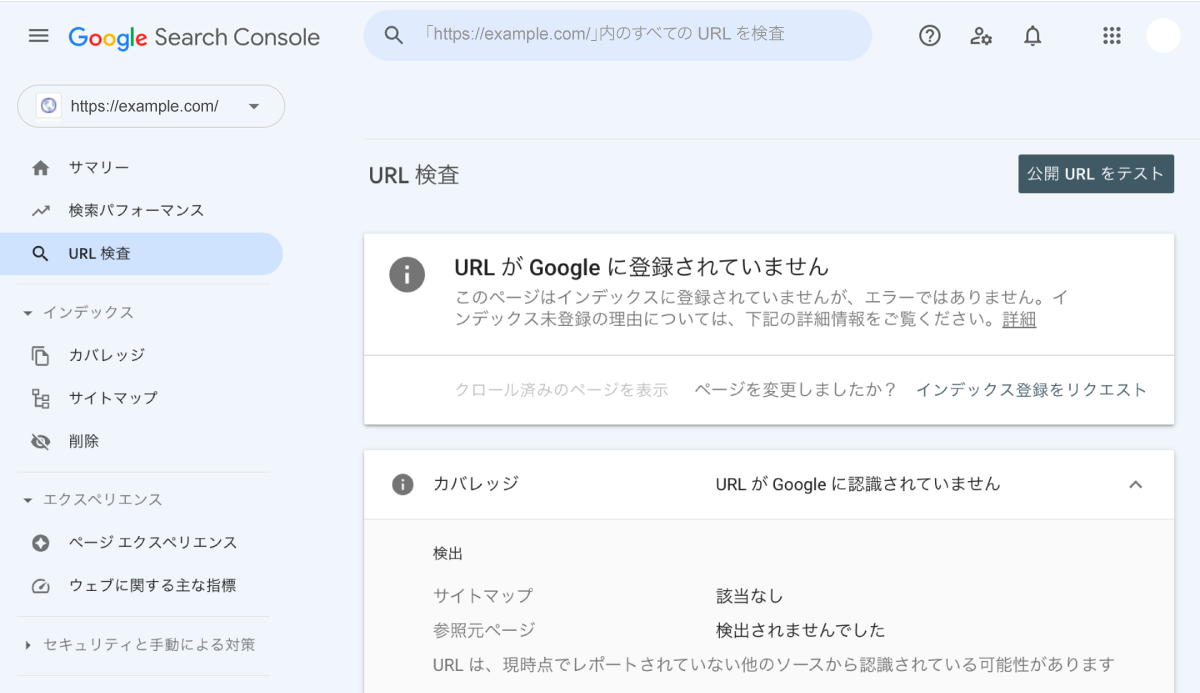
4. インデックスに登録されないとき登録させる方法
「自サイトのページがインデックスされない」
というとき何をすればよいか。
「まずはこれをやって様子見」という初期対応を2つ、ご紹介しよう。
4-1. XMLサイトマップを送信する(サイト全体)
1つめは「XMLサイトマップを送信する」ことだ。これはサイト全体が登録されないときに有効である。
「2-1. クロール」にて、“クローラーはリンクをたどってやってくる”と述べた。
じつはWebページ内で自然に設置されたリンクではないルートでクローラーを呼ぶ方法があり、それがXMLサイトマップである。
XMLサイトマップとは?
XMLサイトマップとは、簡単にいうとクローラーに見せるためのサイトマップで、実体は「○○.xml」というファイル名で作成されたURLのリストだ。
▼ サイトマップの例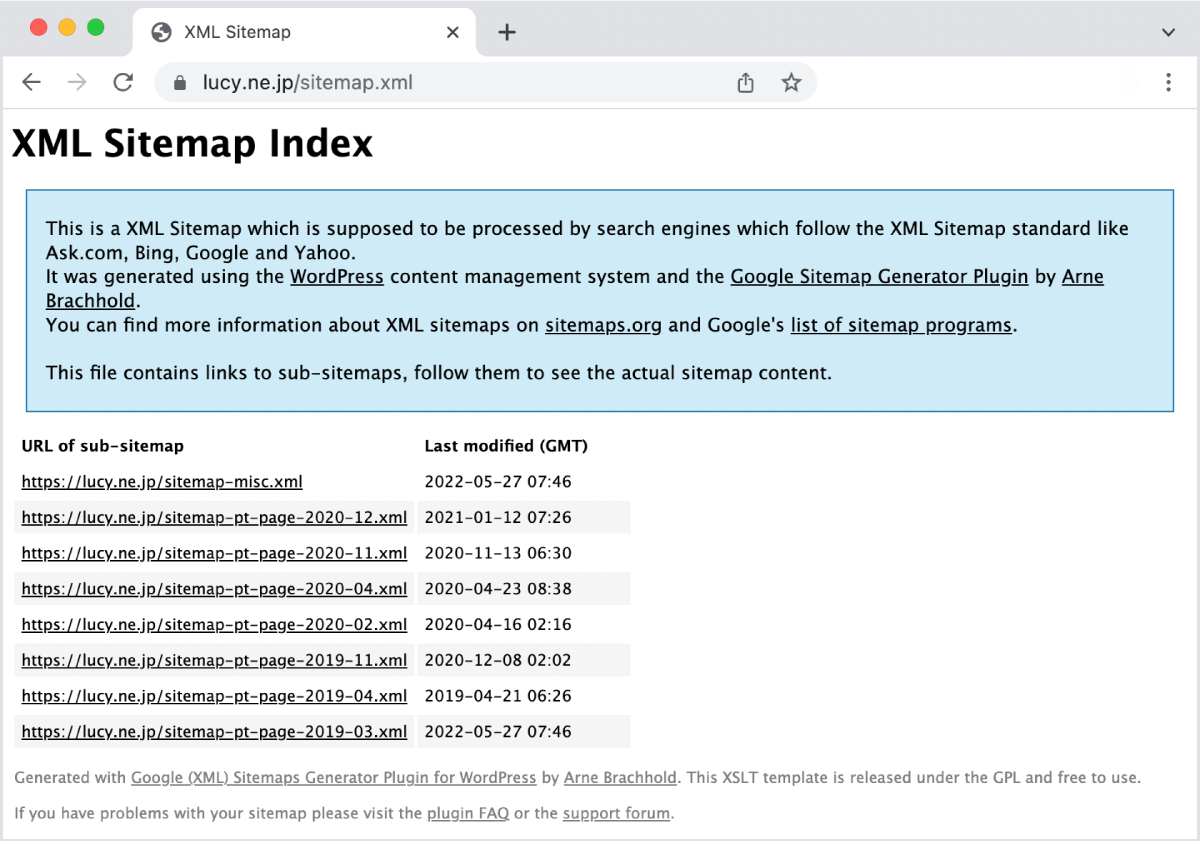
XMLサイトマップには、クロールしてほしいURLがリストアップされているので、クローラーはページ別にリンクをたどる手間を省いて、効率的に各ページにアクセスできる。
XMLサイトマップの作り方
XMLサイトマップは、自動生成できるツールが用意されている。それらを利用すると簡単に作成できる(例:sitemap.xml Editor)。
WordPressを利用している場合は、WordPressのプラグインで自動生成するのが一般的なやり方だ。
もし「All in One SEO」というプラグインがすでに導入されていれば、All in One SEOにXMLサイトマップ機能があるので、それを使う。
XMLサイトマップ機能のあるプラグインをインストールしておらず、新たにインストールする場合には、「Google XML Sitemaps」がおすすめだ。
それぞれ以下の記事で詳説しているので、参考にしてほしい。
|
作ったXMLサイトマップの送り方
作成したXMLサイトマップは、Search ConsoleからGoogleに送信できる。
|
…という手順だ。
Search Consoleの「新しいサイトマップの追加」にXMLサイトマップのURLを入力し、送信する。
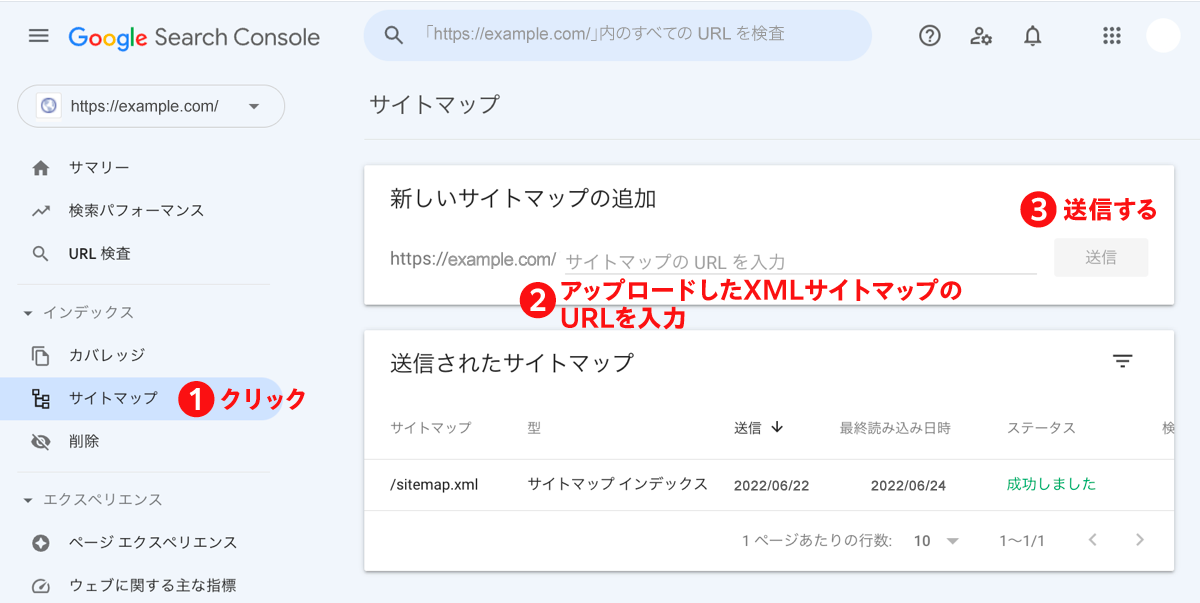
なお、WordPressのプラグインを利用する場合は、ファイル生成からGoogleへの送信まで自動的に行われるため、この作業は本来は必要ない。
ただ、この作業をして何か害があるわけではないので、
「少しでも早くインデックス登録させたい」
というときには、手作業で送信しておくとよいだろう。
XMLサイトマップが必要なサイト・不要なサイト
ここでひとつ補足がある。Googleが、XMLサイトマップが必要なサイト・不要なサイトを以下のとおりレクチャーしている。

「XMLサイトマップが必要なサイト」に該当するにもかかわらず、今まで作っていなかったのであれば、XMLサイトマップによってインデックス登録状況が改善する可能性が高い、と判断できる。
4-2. インデックス登録のリクエストを送信する(特定URL)
XMLサイトマップはサイト全体のクロールを要求するものだが、
「特定のURLだけ、インデックス登録されない」
という状況のときには、「インデックス登録のリクエストを送信する」という方法がある。
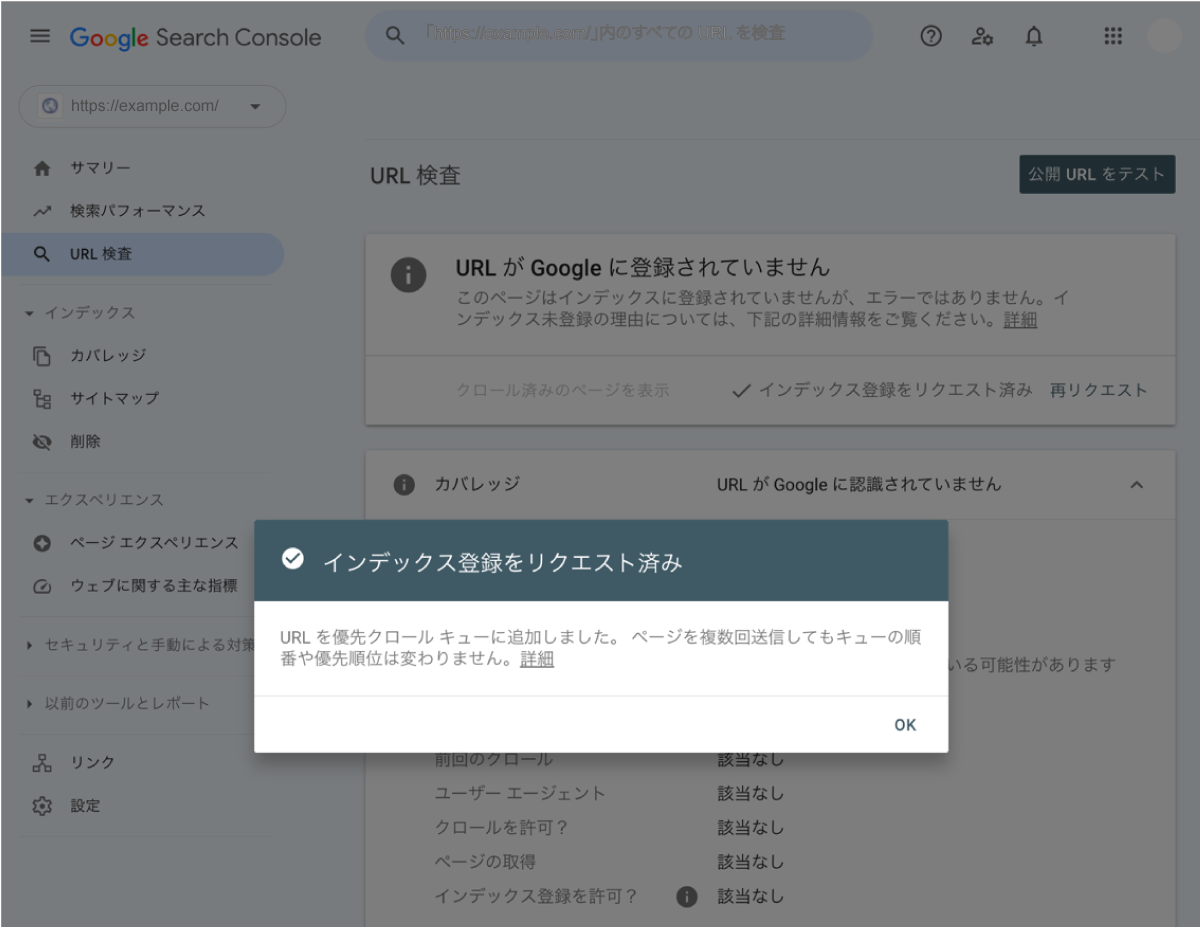
「特定URLは「URL検査」」にて紹介したやり方でURL検査をした後、結果画面から[インデックス登録をリクエスト]をクリックするだけだ。
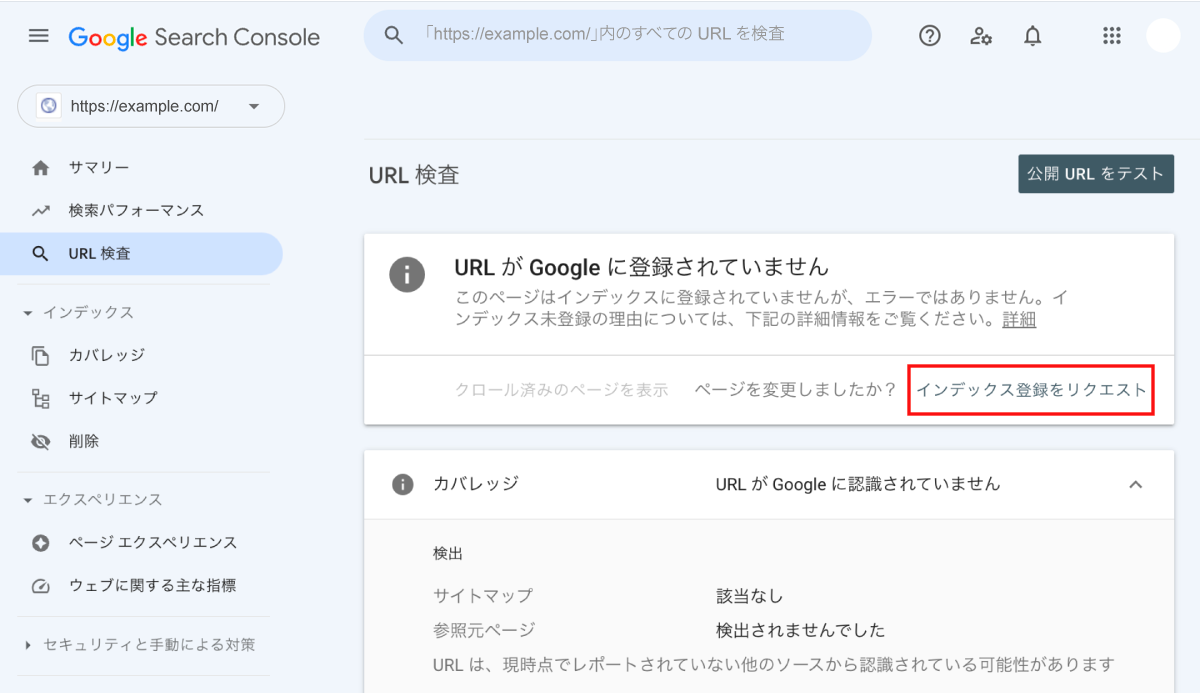 リクエストの送信が完了すると、以下のダイアログが表示される。
リクエストの送信が完了すると、以下のダイアログが表示される。
5. インデックス登録を「不許可」にする設定
インデックスの登録方法とあわせて知っておいてほしいのが、インデックス登録を不許可にする設定だ。
なぜなら、インデックスされないトラブルに遭遇したときには、まずこれらの不許可設定がなされていないか確認する必要があるからである。
インデックスを不許可にするやり方は大きく分けて2つある。
 クロールを拒否する方法と、インデックス登録を拒否する方法だ。それぞれ詳しく見ていこう。
クロールを拒否する方法と、インデックス登録を拒否する方法だ。それぞれ詳しく見ていこう。
5-1. クロールを拒否する
「Googlebotは、検出したすべてのページをクロールするわけではない」とGoogle公式サイトでも述べられている。

クロールを不許可にする方法はこちらのリンクから詳細を確認できる。
robots.txtの設定手順
簡単に手順だけ紹介しよう。
|
「クロールするな」の指示の書き方は、以下のとおりだ。
User-agent: *
disallow: [path]
「User-agent: *」でブロックしたいクローラーを指定する。
- 例1:User-agent: * → すべてのクローラー
- 例2:User-agent: Googlebot → Googlebot
「disallow: [path]」でクロールを拒否するディレクトリやページを相対URLで指定する。
- 例1:disallow: /contents/ → contentsディレクトリ
- 例2:disallow: /contents/test.html → contents/test.html
▼ 例:contents/test.htmlに対するすべてのクロールを不許可にする
User-agent: *
disallow:contents/test.html
※robots.txtの詳しい作成方法はGoogleの「robots.txt ファイルを作成して送信する」にて解説されている。
robots.txtに強制力はない
注意点としてrobots.txt ファイルの指示に強制力はない。
指示に従うかどうかはクロール次第で、Googleは、
「Googlebot などの信頼できるクローラーは指示に従うが、他のクローラーも従うとは限らない」
と注意喚起している。
確実にクローラーをブロックしたいのであれば、クローラーがアクセスできない認証をかけてページを保護するか、ネット上にアップロードするのをやめるかしかない。
▼ 参考:Googleの注意喚起
現状の robots.txt の確認方法
現状のrobots.txtがどうなっているのか(あるのか、ないのか、あるなら何が書かれているのか)を確認するためには、以下のURLにアクセスすればよい。
| https://ドメイン名/robots.txt |
※「ドメイン名」には自サイトのドメインを入力する。
WordPressを使用している場合は、デフォルトで以下の内容が表示されるだろう。
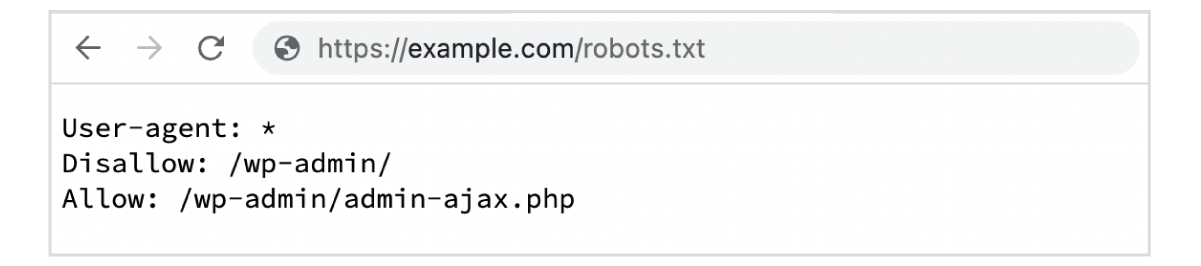
管理画面のディレクトリ(wp-admin)へのクロールを拒否(admin-ajax.phpのみ許可)という指定になっている。
5-2. インデックス登録を拒否する
2つめの、クロールされたデータのインデックス登録を拒否する方法は、メタタグのひとつである「noindex」を使う。
noindexタグ
メタタグとは<meta 〜>で始まるタグで、ページの<head>と</head>の間に記述する。
<!DOCTYPE html>
<html><head>
<meta name=”robots” content=”noindex” />
(…)
</head>
<body>(…)</body>
</html>
ページ単位で簡単に設定できるメリットがある。HTMLに自分で書き込むほか、プラグインを利用する方法もある。
詳しくは「noindexの使い方」にて解説しているので、参照してほしい。
noindexタグとrobots.txtは併用できない
注意点として、noindexタグとrobots.txtは併用できない。
その理由は、robots.txtでクロールを禁止すると、クローラーはHTMLの中身を見ることができず、noindexタグが書かれていても見られないからだ。
ではどちらを使えばよいのか?というと、Googleはnoindexタグのほうを推奨している。
現状の noindex の確認方法
自サイトのWebページで現状のnoindexがどうなっているか確認するためには、ページのソースを確認すればよい。
ページのソースコードは、Webブラウザ上で簡単に表示できる。
表示方法はブラウザによって異なるが、主要なブラウザ(Chrome、Safari、Edgeなど)は、ページ上で右クリックすると、[ページのソースを表示]というメニューが表示されるはずだ。
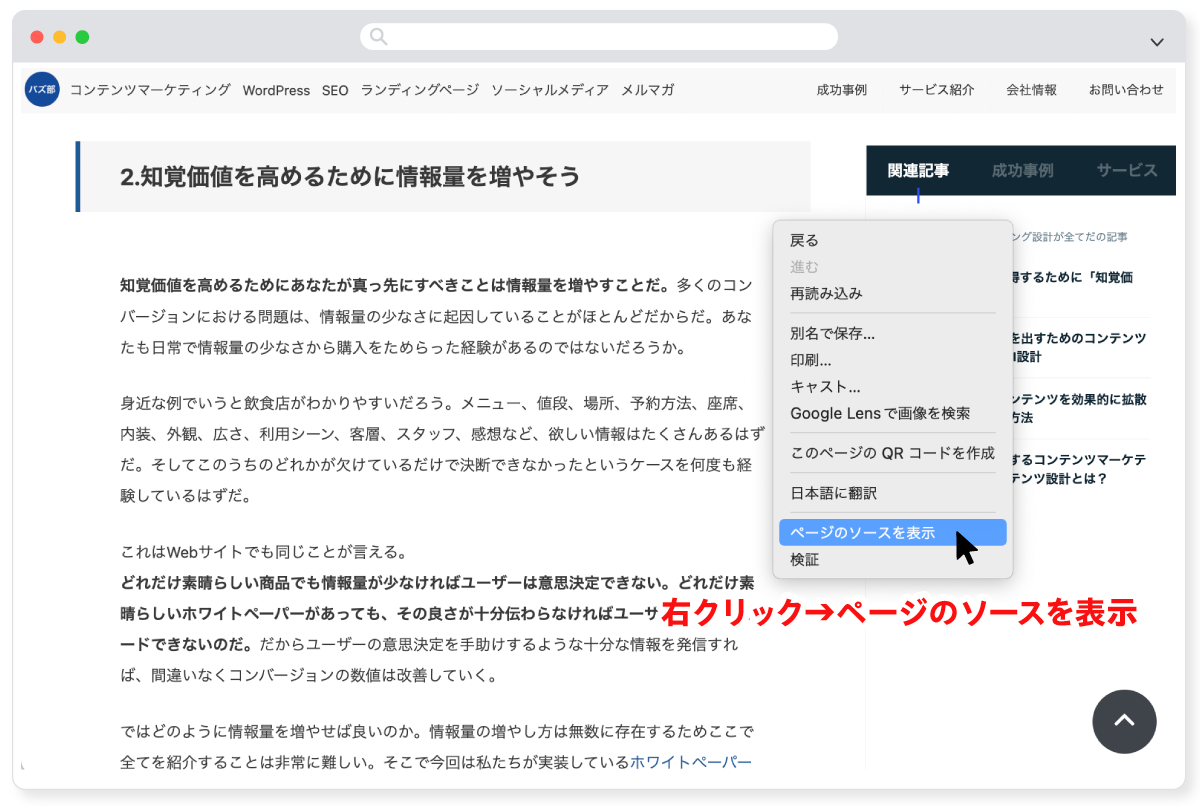 以下のようにコードが表示されたら、<head>と</head>の間に、<meta name=”robots” content=”noindex” />の記述がないか探す。「noindex」で検索をかけるのが早いだろう。
以下のようにコードが表示されたら、<head>と</head>の間に、<meta name=”robots” content=”noindex” />の記述がないか探す。「noindex」で検索をかけるのが早いだろう。
6. インデックス登録されないとき確認すべきポイント
「4. インデックスに登録されないとき登録させる方法」で紹介した初動対応を行ってもインデックス登録がされないときには、以下のポイントを確認してほしい。
|
それぞれ見ていこう。
6-1. 不許可設定をしていないか
1つめのポイントは「不許可設定をしていないか」である。
さきほど「5. インデックス登録を「不許可」にする設定」にて解説したrobots.txtやnoindexタグで、インデックスを拒否していないだろうか。
「もう確認した」という場合も、いま一度、見直しをしよう。それほど、不許可設定のケアレスミスは多いからだ。
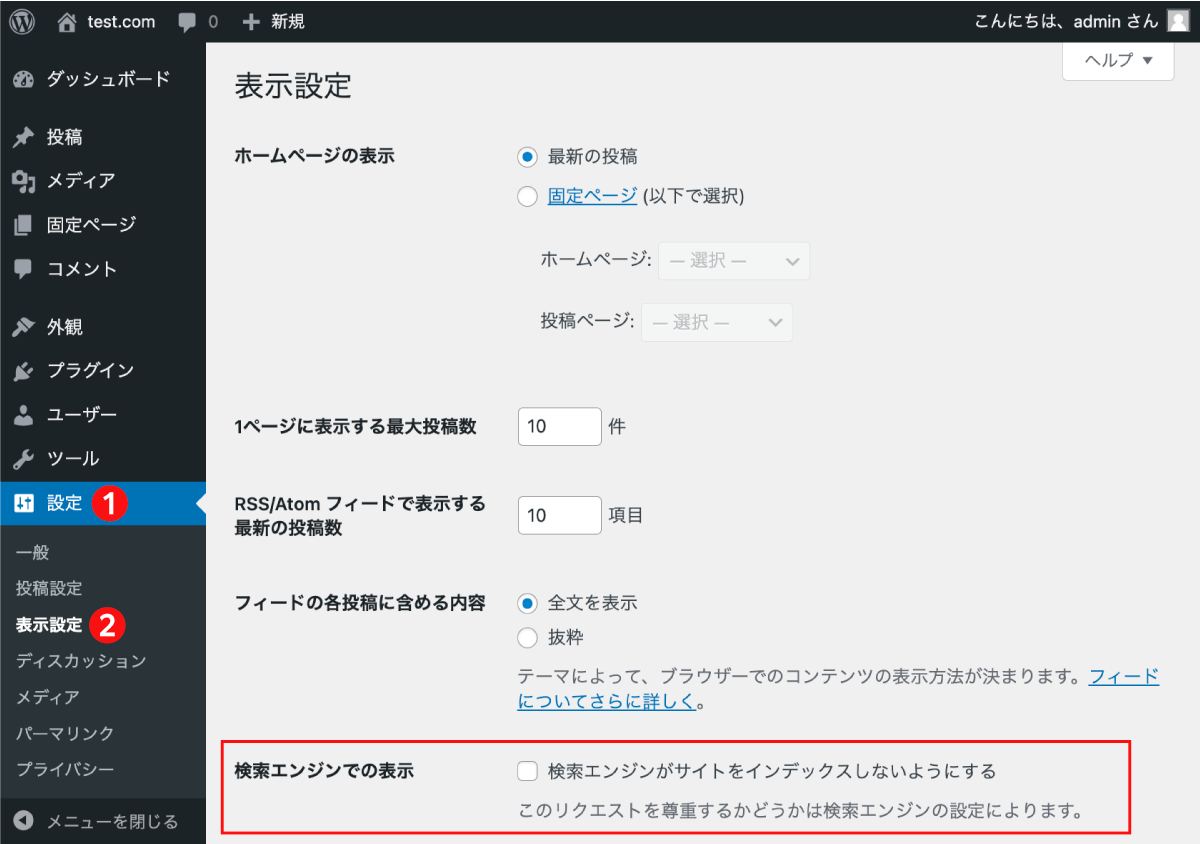
WordPressの場合、立ち上げたときに「完成するまでインデックスされないようにしよう」と管理画面で設定したまま忘れている、というケースもある。
[設定]→[表示設定]に設定項目があるので、確認してみてほしい。
6-2. ほかのページと重複していないか
2つめのポイントは「ほかのページと重複していないか」である。
Googleは、複数のURLで重複したコンテンツがあるときは、そのうちの1つを「正規URL」として選択し、クロールする。
正規URLとして採用されなかったその他のURLはすべて重複URLとみなされ、クロールの頻度が減る。
類似ページ・重複ページは、さまざまな理由で発生するので注意が必要だ。

どのURLを正規URLに採用するか?は、Google次第となる。
サイト運営者の視点から見て、インデックス登録してほしいURLであっても、ほかのページの重複版とみなされてしまうと、クローラーが来てくれなくなる。
これを回避する方法として、どれが正規URLか、サイト運営者側で明示的に指定する方法がある(これを正規化という)。
▼ 正規化の方法と説明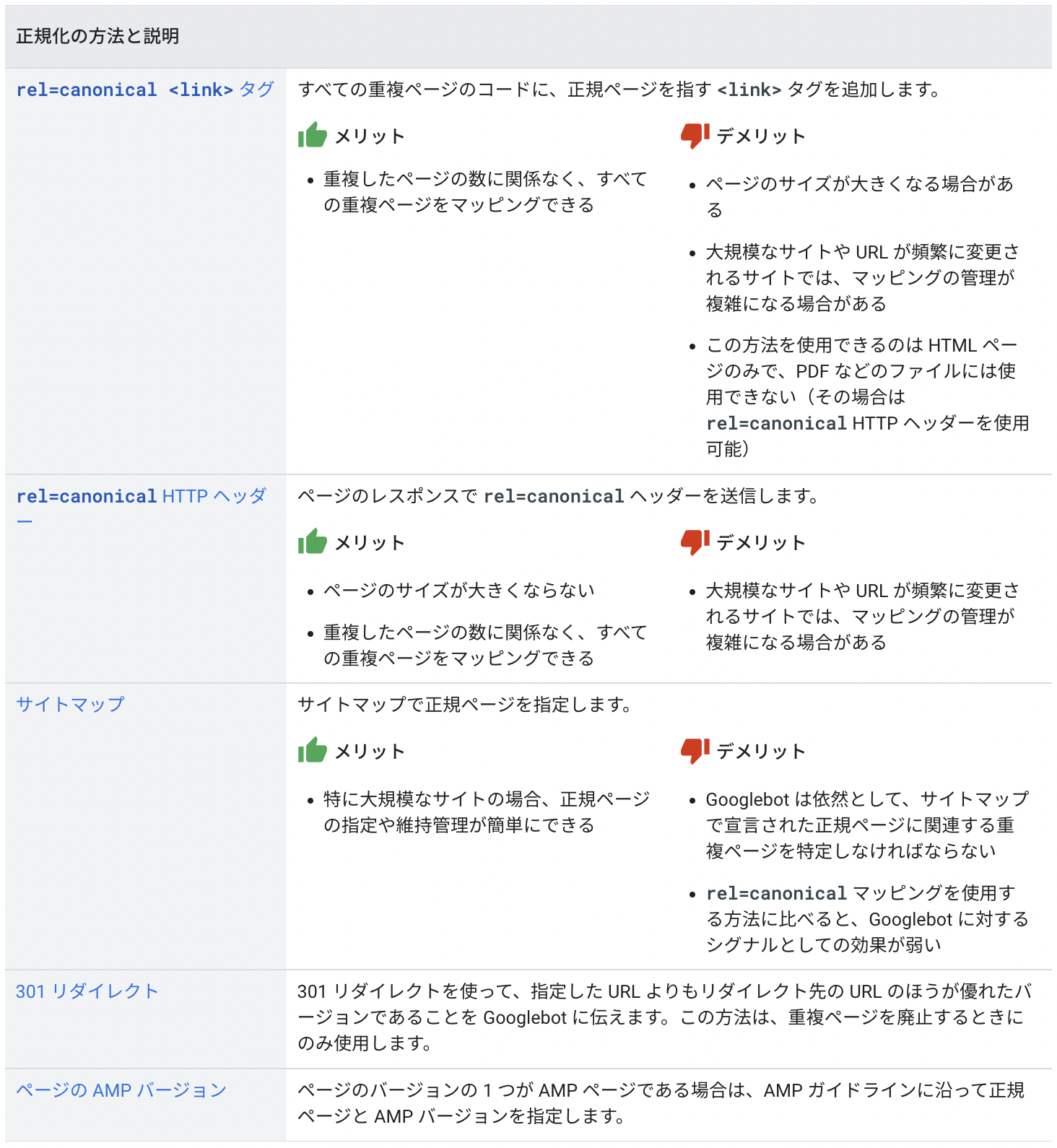
詳しくはGoogleの「重複した URL を正規 URL に統合する」にて解説されている。
また、重複URLを含む重複コンテンツについては「重複コンテンツとは?SEOへの影響とチェック方法・8つの内部対策」にて詳しく取り上げたので、あわせて確認してほしい。
6-3. 内部リンクが適切にされているか
3つめのポイントは「内部リンクが適切にされているか」である。
内部リンクが不十分でもフォローできる方法として「XMLサイトマップ」を紹介した。
しかし、XMLサイトマップもまた、インデックスされる保証があるわけではない点に注意したい。
クローラーの挙動の基本は「リンクをたどる」であるから、適切に内部リンク(サイト内のページ同士を結ぶリンク)が設置されている状態が理想だ。
内部リンクの張り方については、別記事の「内部リンクとは?SEOでの重要性と効果が出る張り方のコツ」にて、以下のエッセンスを解説している。
▼ 重要な4つのエッセンス
|
目を通して内部リンク改善に役立ててほしい。
6-4. ページのコンテンツ品質が低くないか
4つめのポイントは「ページのコンテンツ品質が低くないか」である。
著しいレベルでページの品質が低い場合、インデックスされないことがある。
とはいえ、インデックスのハードルは高くはないので、コンテンツの磨き上げをするよりもまず、最低限のガイドラインを守れているのか、振り返る必要がある。
以下にGoogleサイトからのガイドラインを引用するので、確認してみてほしい。
▼ 具体的なガイドライン:次のような手法を使用しないようにします。
- 検索ランキングを操作することを目的としている自動生成コンテンツ
- リンク プログラムへの参加
- オリジナルのコンテンツがほとんどまたはまったく存在しないページの作成
- クローキング
- 不正なリダイレクト
- 隠しテキストや隠しリンク
- 誘導ページ
- 無断複製されたコンテンツ
- 十分な付加価値のないアフィリエイト サイト
- ページへのコンテンツに関係のないキーワードの詰め込み
- フィッシングや、ウイルス、トロイの木馬、その他のマルウェアのインストールといった悪意のある動作を伴うページの作成
- 構造化データのマークアップの悪用
- Google への自動化されたクエリの送信
こういった最低限のガイドラインを遵守する体制が整ったら、次のステップとしてユーザーにとって魅力あるコンテンツに邁進してほしい。
本腰を入れて価値あるコンテンツづくりに取り組みたい方には、「バズ部が教えるコンテンツマーケティング101」の情報が役立つだろう。
6-5. ネットワークやサイト処理など技術的な問題がないか
5つめのポイントは「ネットワークやサイト処理など技術的な問題がないか」である。
ここまでの4つのポイントをクリアしてもインデックスされない場合、ネットワークやサイトの処理など技術的な問題が発生している可能性がある。
以下に可能性のある問題を例示するので確認してみてほしい(リンク先はGoogleサイト)。
7. インデックスを削除したいときの対応
最後に、すでにGoogleに登録されたインデックスを、何らかの事情で削除したいときの対応を紹介しておく。
7-1. 一時的な削除(6ヶ月以内)
一時的に削除したい場合(6ヶ月以内)は、Search Consoleから削除のリクエストが可能だ。
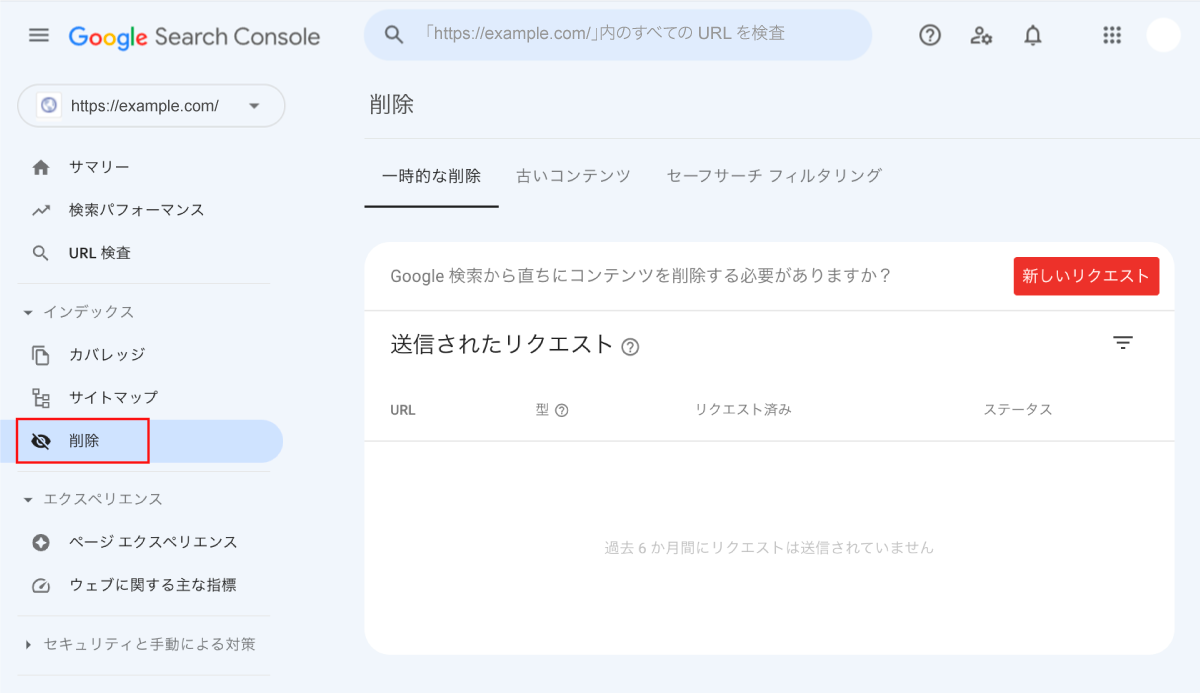
Search Consoleの[インデックス]→[削除]から削除の画面にアクセスできる。
[新しいリクエスト]をクリックすると、以下の画面に遷移するので、削除したいURLを入力しよう。
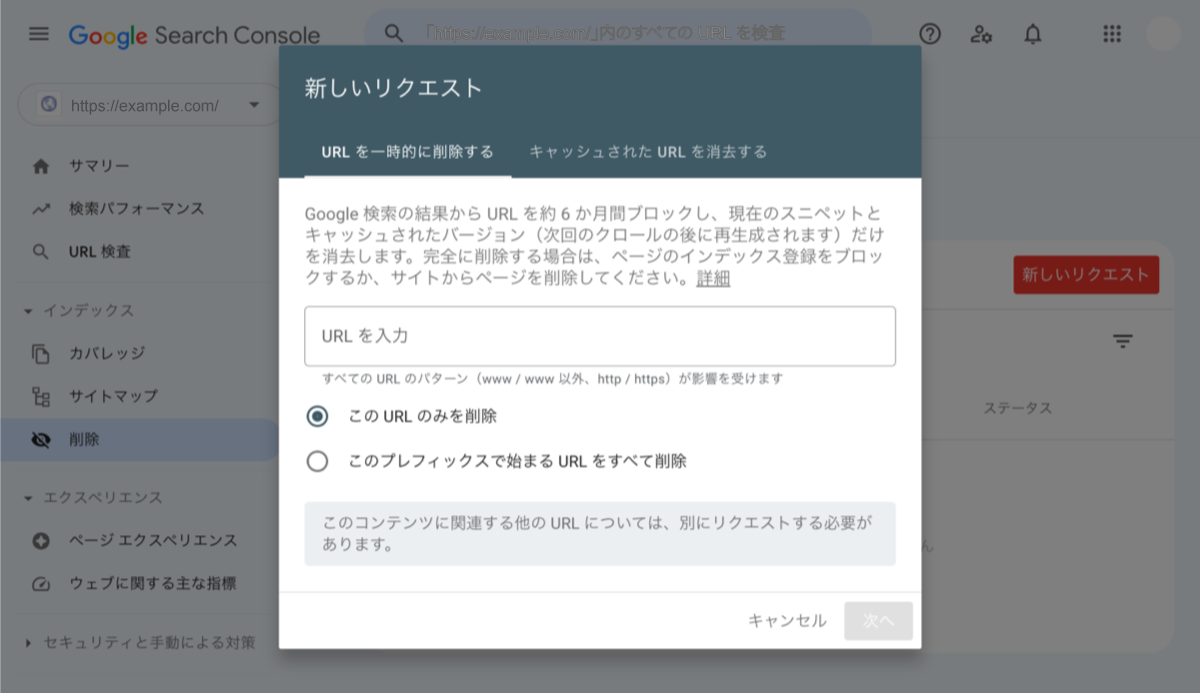
7-2. 完全な削除(6ヶ月以上)
先ほどの新しいリクエストの入力画面には、以下の注意書きが記載されている。
Google 検索の結果から URL を約 6 か月間ブロックし、現在のスニペットとキャッシュされたバージョン(次回のクロールの後に再生成されます)だけを消去します。完全に削除する場合は、ページのインデックス登録をブロックするか、サイトからページを削除してください。
よって6ヶ月以上の期間にわたって削除したい場合には、「完全に削除する」にて案内されている以下の手順を踏む必要がある。

インデックスされたくないページの対処が必要になったときには、参考にしてほしい。
8. まとめ
本記事では「seo インデックス」をテーマに解説した。要点を簡単にまとめよう。
インデックス登録とは、Googleのクローラーが収集したWebページのデータを、データベース化してインデックス(膨大なデータベース)へ格納することをいう。
自サイトのページがインデックスされないときの対処法は、以下のとおりだ。
▼ 初動対応
|
初動対応で改善しなかった場合は、次のポイントを確認する。
▼ 確認ポイント
|
「インデックスされること」は、SEOの大切な第一歩だ。ここから、 世界につながる。
本記事を通してGoogleの特性の一端をつかみつつ、世界のユーザーに価値を届けるサイト構築に励んでいただければと思う。